llama3源码解析-04:generation.py模块解析
Last updated on December 30, 2024 am

整体
generation.py 模块是 Llama 3 模型的核心生成模块,负责实现文本生成功能,包括文本补全和对话生成。
1. 核心功能
- 文本生成:根据输入的提示(prompt)生成文本。
- 文本补全:对给定的文本提示进行补全。
- 对话生成:根据对话历史生成助理的回复。
- 生成控制:支持通过温度(temperature)、top-p 采样(nucleus sampling)等参数控制生成过程。
2. 主要类和方法
class Llama
build方法:初始化并加载 Llama 模型和分词器。generate方法:核心生成方法,根据输入的 tokenized prompts 生成文本。text_completion方法:对文本提示进行补全。chat_completion方法:根据对话历史生成助理的回复。
class CompletionPrediction
- 用于表示文本补全的生成结果,包含生成的文本、token 列表和 logprobs(可选)。
class ChatPrediction
- 用于表示对话生成的生成结果,包含助理的回复、token 列表和 logprobs(可选)。
3. 核心方法详解
generate 方法
- 功能:根据输入的 tokenized prompts 生成文本。
- 参数:
prompt_tokens:tokenized prompts,形状为(batch_size, seq_len)。max_gen_len:生成文本的最大长度。temperature:控制生成随机性的温度参数。top_p:top-p 采样的概率阈值。logprobs:是否计算 token 的 log 概率。echo:是否在生成结果中包含输入提示。
- 返回值:生成的 token 序列和 logprobs(可选)。
text_completion 方法
- 功能:对文本提示进行补全。
- 参数:
prompts:文本提示列表。temperature:控制生成随机性的温度参数。top_p:top-p 采样的概率阈值。max_gen_len:生成文本的最大长度。logprobs:是否计算 token 的 log 概率。echo:是否在生成结果中包含输入提示。
- 返回值:文本补全的生成结果列表。
chat_completion 方法
- 功能:根据对话历史生成助理的回复。
- 参数:
dialogs:对话历史列表。temperature:控制生成随机性的温度参数。top_p:top-p 采样的概率阈值。max_gen_len:生成文本的最大长度。logprobs:是否计算 token 的 log 概率。
- 返回值:对话生成的生成结果列表。
4. 生成控制参数
- 温度(temperature):
- 控制生成随机性的参数。
- 值越大,生成结果越随机;值越小,生成结果越确定。
- top-p 采样(nucleus sampling):
- 从概率累积值超过
top_p的最小 token 集合中采样。 - 用于控制生成结果的多样性和质量。
- 从概率累积值超过
- logprobs:
- 是否计算生成 token 的 log 概率。
- 用于分析生成结果的置信度。
5. 生成流程
- 输入处理:
- 将输入提示或对话历史转换为 tokenized prompts。
- 生成文本:
- 使用
generate方法生成 token 序列。 - 通过温度、top-p 采样等参数控制生成过程。
- 使用
- 输出处理:
- 将生成的 token 序列解码为文本。
- 返回生成结果,包含生成的文本、token 列表和 logprobs(可选)。
6. 示例
文本补全
1 | |
对话生成
1 | |
7. 总结
generation.py 模块是 Llama 3 模型的核心生成模块,提供了文本补全和对话生成功能。通过温度、top-p 采样等参数,用户可以灵活控制生成过程。
build 方法
1 | |
详细解释
1. 参数检查
max_seq_len: 检查输入序列的最大长度是否在有效范围内(1 到 8192)。ckpt_dir: 检查检查点目录是否存在。tokenizer_path: 检查分词器文件是否存在。
2. 分布式初始化
- 如果分布式进程组未初始化,则使用
torch.distributed.init_process_group初始化。 - 如果模型并行未初始化,则根据
model_parallel_size或环境变量初始化模型并行。
3. 设备设置
- 获取当前进程的本地 rank,并设置使用的 GPU 设备。
4. 随机种子
- 设置随机种子,确保所有进程的随机性一致。
5. 检查点加载
- 获取检查点目录中的所有
.pth文件,并按文件名排序。 - 检查检查点文件数量和模型并行大小是否匹配。
- 加载当前进程对应的检查点文件到 CPU。
6. 模型参数加载
- 从
params.json文件中加载模型参数。 - 使用
ModelArgs初始化模型参数。
7. 分词器初始化
- 使用
Tokenizer初始化分词器,并检查模型词汇表大小是否与分词器词汇表大小匹配。
8. 张量类型设置
- 如果当前设备支持
bfloat16,则设置默认张量类型为bfloat16,否则设置为float16。
9. 模型初始化
- 使用
Transformer初始化模型,并加载检查点中的权重。
10. 返回 Llama 实例
- 返回包含加载的模型和分词器的
Llama实例。
总结
build 方法负责初始化并加载 Llama 模型,包括分布式设置、设备配置、检查点加载、模型参数初始化、分词器初始化等。它是 Llama 模型的核心初始化方法,确保模型能够正确加载并准备好进行推理或训练。
generate 方法
1 | |
详细解释
1. 输入处理
prompt_tokens: 输入的 tokenized prompts,每个 prompt 是一个整数列表。max_gen_len: 生成文本的最大长度。temperature: 控制生成随机性的温度参数。top_p: top-p 采样的概率阈值。logprobs: 是否计算 token 的 log 概率。echo: 是否在生成结果中包含输入提示。
2. 初始化
params: 获取模型参数。bsz: 获取批次大小。min_prompt_len和max_prompt_len: 计算输入 prompts 的最小和最大长度。total_len: 计算总长度(输入 prompts 长度 + 生成文本长度)。tokens: 初始化 tokens 张量,用 pad_id 填充,并将输入 prompts 填充到 tokens 张量中。
3. 生成文本
- 逐 token 生成:
- 使用
model.forward计算当前 token 的 logits。 - 如果
temperature > 0,则使用温度参数和 top-p 采样生成下一个 token。 - 如果
temperature = 0,则选择概率最大的 token。 - 将下一个 token 填充到 tokens 张量中。
- 如果
logprobs为 True,则计算 token 的 log 概率。 - 检查是否生成停止 token,如果所有批次都生成停止 token,则提前结束。
- 使用
4. 输出处理
out_tokens和out_logprobs: 处理每个批次的生成结果。- 如果
echo为 False,则从生成部分开始截取。 - 如果生成结果中包含停止 token,则截取到停止 token 之前。
- 如果
- 返回结果: 返回生成的 token 序列和 logprobs(可选)。
总结
generate 方法是 Llama 3 模型的核心生成方法,负责根据输入的 tokenized prompts 生成文本。通过温度、top-p 采样等参数,用户可以灵活控制生成过程。该方法支持计算 token 的 log 概率,并可以处理停止 token 和输入提示。
generate 详细流程图
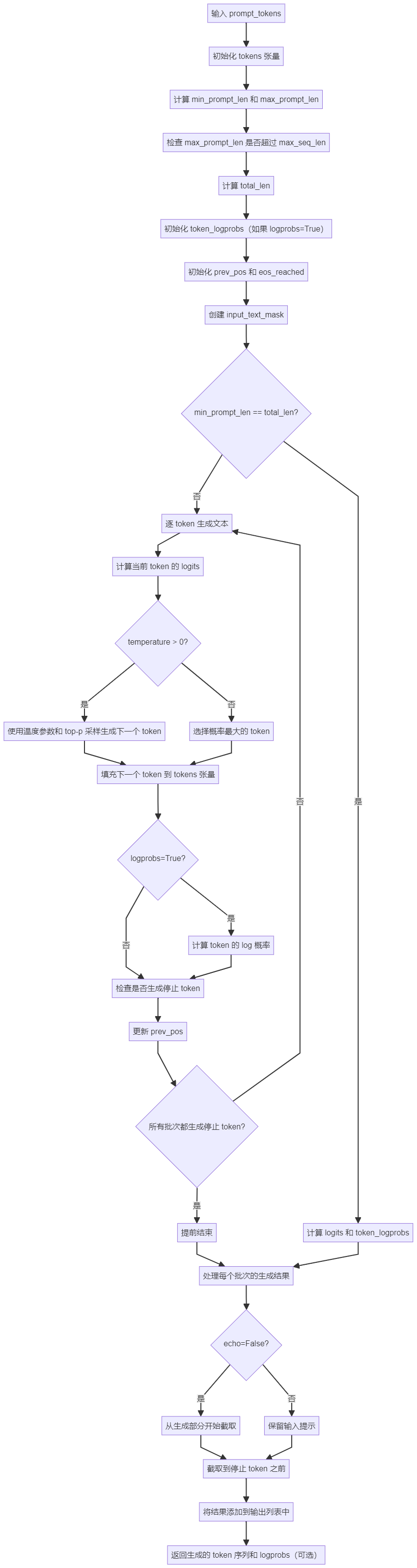
详细步骤说明
1. 输入处理
- 输入:
prompt_tokens,tokenized prompts,每个 prompt 是一个整数列表。
2. 初始化
- 初始化 tokens 张量: 用 pad_id 填充,并将输入 prompts 填充到 tokens 张量中。
- 计算 min_prompt_len 和 max_prompt_len: 输入 prompts 的最小和最大长度。
- 检查 max_prompt_len 是否超过 max_seq_len: 确保输入 prompts 的长度不超过模型的最大序列长度。
- 计算 total_len: 输入 prompts 长度 + 生成文本长度。
- 初始化 token_logprobs: 如果
logprobs=True,则初始化 token_logprobs 张量。 - 初始化 prev_pos 和 eos_reached: 当前位置和 EOS(结束符)标记。
- 创建 input_text_mask: 输入文本的掩码(非填充部分为 True)。
3. 生成文本
- 检查 min_prompt_len 是否等于 total_len:
- 如果相等,则直接计算 logits 和 token_logprobs。
- 否则,逐 token 生成文本。
- 逐 token 生成文本:
- 计算当前 token 的 logits。
- 检查 temperature 是否大于 0:
- 如果大于 0,则使用温度参数和 top-p 采样生成下一个 token。
- 否则,选择概率最大的 token。
- 填充下一个 token 到 tokens 张量。
- 检查 logprobs 是否为 True:
- 如果为 True,则计算 token 的 log 概率。
- 检查是否生成停止 token。
- 更新 prev_pos。
- 检查所有批次是否都生成停止 token:
- 如果是,则提前结束。
- 否则,继续生成下一个 token。
4. 输出处理
- 处理每个批次的生成结果:
- 检查 echo 是否为 False:
- 如果为 False,则从生成部分开始截取。
- 否则,保留输入提示。
- 截取到停止 token 之前。
- 将结果添加到输出列表中。
- 检查 echo 是否为 False:
- 返回生成的 token 序列和 logprobs(可选)。
总结
generate 方法的流程图清晰地展示了从输入到输出的完整生成过程,包括初始化、逐 token 生成和输出处理。通过该流程图,可以更好地理解 Llama 3 模型的文本生成机制。
text_completion 和 chat_completion
1. text_completion 方法
功能
对给定的文本提示进行补全,生成后续文本。
参数
prompts: 文本提示列表,每个提示是一个字符串。temperature: 控制生成随机性的温度参数。值越大,生成结果越随机;值越小,生成结果越确定。top_p: top-p 采样的概率阈值。用于控制生成结果的多样性和质量。max_gen_len: 生成文本的最大长度。如果未提供,则使用模型的最大序列长度减 1。logprobs: 是否计算 token 的 log 概率。默认为 False。echo: 是否在生成结果中包含输入提示。默认为 False。
返回值
List[CompletionPrediction]: 文本补全的生成结果列表,每个结果包含生成的文本、token 列表和 logprobs(可选)。
代码逻辑
- 检查
max_gen_len:- 如果未提供
max_gen_len,则使用模型的最大序列长度减 1。
- 如果未提供
- 编码输入提示:
- 使用分词器将输入提示编码为 tokenized prompts。
- 调用
generate方法:- 使用
generate方法生成 token 序列。
- 使用
- 解码生成结果:
- 将生成的 token 序列解码为文本。
- 返回生成结果:
- 如果
logprobs为 True,则返回生成的文本、token 列表和 logprobs。 - 否则,仅返回生成的文本。
- 如果
示例
1 | |
2. chat_completion 方法
功能
根据对话历史生成助理的回复。
参数
dialogs: 对话历史列表,每个对话是一个消息列表,每个消息包含角色(role)和内容(content)。temperature: 控制生成随机性的温度参数。值越大,生成结果越随机;值越小,生成结果越确定。top_p: top-p 采样的概率阈值。用于控制生成结果的多样性和质量。max_gen_len: 生成文本的最大长度。如果未提供,则使用模型的最大序列长度减 1。logprobs: 是否计算 token 的 log 概率。默认为 False。
返回值
List[ChatPrediction]: 对话生成的生成结果列表,每个结果包含助理的回复、token 列表和 logprobs(可选)。
代码逻辑
- 检查
max_gen_len:- 如果未提供
max_gen_len,则使用模型的最大序列长度减 1。
- 如果未提供
- 编码对话历史:
- 使用
ChatFormat将对话历史编码为 tokenized prompts。
- 使用
- 调用
generate方法:- 使用
generate方法生成 token 序列。
- 使用
- 解码生成结果:
- 将生成的 token 序列解码为文本。
- 返回生成结果:
- 如果
logprobs为 True,则返回助理的回复、token 列表和 logprobs。 - 否则,仅返回助理的回复。
- 如果
示例
1 | |
3. 主要区别
| 特性 | text_completion |
chat_completion |
|---|---|---|
| 输入 | 文本提示列表 | 对话历史列表 |
| 输出 | 文本补全结果 | 助理的回复 |
| 编码方式 | 直接使用分词器编码 | 使用 ChatFormat 编码对话历史 |
| 适用场景 | 单轮文本补全 | 多轮对话生成 |
| 返回格式 | CompletionPrediction |
ChatPrediction |
4. 生成控制参数
- 温度(temperature):
- 控制生成随机性的参数。
- 值越大,生成结果越随机;值越小,生成结果越确定。
- top-p 采样(nucleus sampling):
- 从概率累积值超过
top_p的最小 token 集合中采样。 - 用于控制生成结果的多样性和质量。
- 从概率累积值超过
- logprobs:
- 是否计算生成 token 的 log 概率。
- 用于分析生成结果的置信度。
5. 总结
text_completion: 用于文本补全,适用于单轮文本生成任务。chat_completion: 用于对话生成,适用于多轮对话任务。- 两者都通过
generate方法实现核心生成逻辑,并支持温度、top-p 采样等参数控制生成过程。
sample_top_p
该函数实现了 top-p 采样(nucleus sampling),用于从概率分布中选择 token。
代码注释
1 | |
详细解释
1. 输入参数
probs: 概率分布张量,形状为(batch_size, vocab_size),表示每个 token 的概率。p: top-p 采样的概率阈值,取值范围为(0, 1]。例如,p=0.9表示从概率累积值超过 0.9 的最小 token 集合中采样。
2. 概率排序
torch.sort: 对概率分布进行降序排序,返回排序后的概率probs_sort和对应的索引probs_idx。
3. 计算累积和
torch.cumsum: 计算排序后概率的累积和probs_sum。
4. 创建掩码
mask: 标记概率累积值超过p的 token。例如,如果p=0.9,则掩码标记概率累积值超过 0.9 的 token。
5. 概率置零
probs_sort[mask] = 0.0: 将掩码对应的概率置为 0,排除概率累积值超过p的 token。
6. 归一化
probs_sort.div_: 对剩余的概率进行归一化,使其总和为 1。
7. 多项式采样
torch.multinomial: 从归一化后的概率分布中进行多项式采样,返回采样得到的 token 索引。
8. 获取原始索引
torch.gather: 根据采样结果获取原始 token 索引。
9. 返回结果
next_token: 采样得到的 token 索引,形状为(batch_size, 1)。
示例
假设有以下概率分布和参数:
probs:[[0.1, 0.4, 0.2, 0.3]],形状为(1, 4)。p:0.9。
执行步骤
- 排序:
probs_sort:[[0.4, 0.3, 0.2, 0.1]]。probs_idx:[[1, 3, 2, 0]]。
- 计算累积和:
probs_sum:[[0.4, 0.7, 0.9, 1.0]]。
- 创建掩码:
mask:[[False, False, True, True]]。
- 概率置零:
probs_sort:[[0.4, 0.3, 0.0, 0.0]]。
- 归一化:
probs_sort:[[0.57, 0.43, 0.0, 0.0]]。
- 多项式采样:
next_token:[[1]](假设采样结果为 1)。
- 获取原始索引:
next_token:[[3]]。
返回结果
next_token:[[3]]。
总结
sample_top_p 函数实现了 top-p 采样(nucleus sampling),用于从概率分布中选择 token。通过控制概率阈值 p,可以灵活调整生成结果的多样性和质量。该函数是 Llama 3 模型生成过程的核心组件之一。
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
