公众号“看图学”试题合集(1)
Last updated on February 11, 2025 pm
1.如何让大模型输出合法的Json格式
后处理
最容易想到的当然是重试机制,在 Prompt 中要求 LLM 输出 json,拿到 LLM 的完整输出,判断是否是合法的 json。如果不是,则再重新生成一遍。
当然这里也有优化空间,比如可以通过 json parser 来判断解析到哪里出错了,重试的时候不需要从头输出了,而只需要从出错的地方往后输出即可。
比如 strict-json 库就采用的这种方法。
这属于后处理的方法,最容易实现,但是逼格似乎不太够,而且有点费钱。
约束解码
另一种复杂一点的方法就是约束解码,保证一次性生成合法的 json。
约束解码就是在生成下一个 token 的时候,对词表进行一次筛选,将词表符合约束的 token 留下,其他的 token 都 mask 掉,这样 LLM 在 generate 的时候,每一个时刻的 response 都是符合实现约束的条件的。
举一个例子来说,我们定义了输出的格式为 json,那么第一个字符就必须是 { 符号,词表中其他的 token 都被 mask 掉了。
那第二个字符合法的有, 引号",空白字符还有 },其余的符号都被 mask 掉了。剩余的步骤也一样,直到生成完整的 json 就停止。
上面说的是比较简单的情况,有时候还需要约束 json 符合固定的格式,比如第一个 key 是 name,第二个 key 是 age 之类的。这个时候就要采用一些 Grammar Engine 来负责这些 schema 的处理。
其流程如下:

示意代码如下(暂不考虑 kvcache):
1 | |
通过上面图示和代码可以很清晰的看到约束生成的大概框架。
目前已经有很多框架支持约束解码,比如 Guidance (Guidance AI, 2023), Outlines (Willard & Louf, 2023), XGrammar (Dong et al., 2024) and the grammar module of Llamacpp (Gerganov & al., 2023)。
这些框架在这个基本框架上进一步做了很多优化,比如 mask 的计算和 LLM forward 的流程是可以并行的,然后 Grammer Engine 的处理通常比较耗时,可以加入缓存来提高重复或者相似的语法结构的处理,也有提前计算 mask 以达到加速的目的,因为 mask 可以在 cpu 上计算,对于算力的占用没有那么紧张。
Grammar Engine 内部的一些优化细节就涉及到编译原理了,会有很多自动机相关的研究,这里就不再展开了。
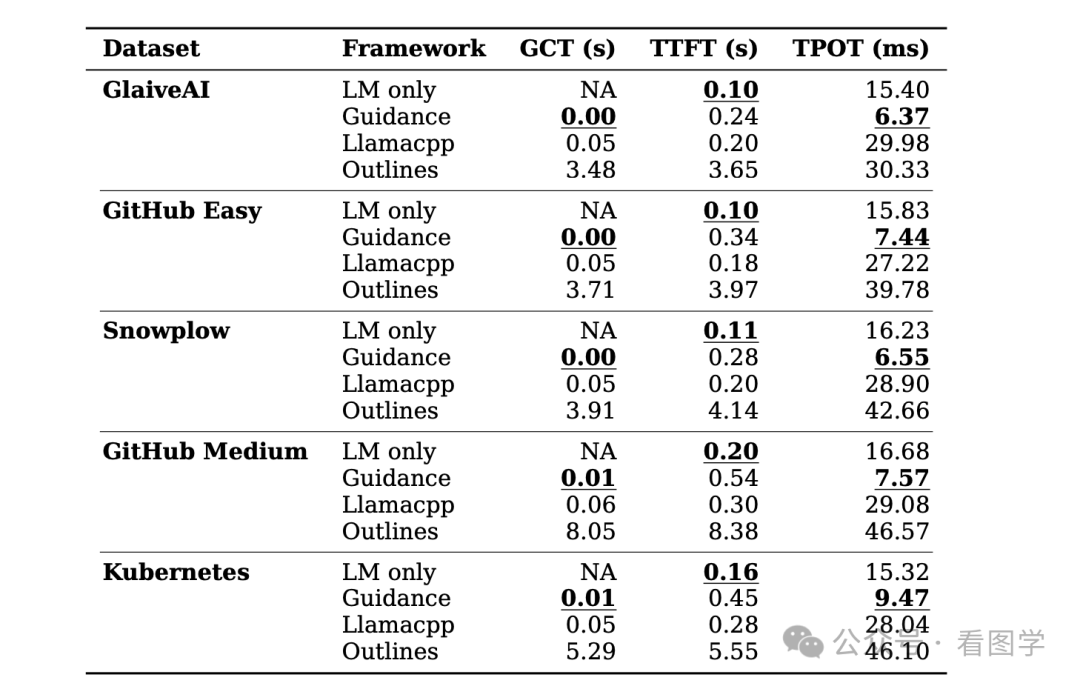
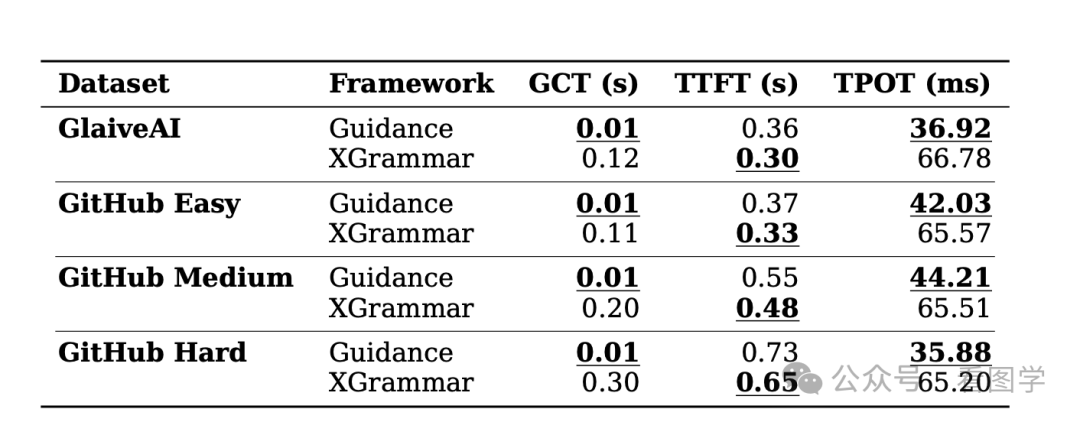
在论文 《Generating Structured Outputs from Language Models: Benchmark and Studies》 中,作者比较了上面几种常用的框架,结果如下:
- GCT 是语法编译的时间(Grammar Compilation Time)
- TTFT 是第一个 token 产出的时间(Time to First Token)
- TPOT 是产生第一个 token 之后,每个 token 的平均生成时间(Time per Output Token (TPOT))
Deepseek一面:“如何让大模型输出合法的 Json 格式?”
2. FIM (Fill in the Middle) 的原理是什么?
假设有这么一个填空题:白日依山尽,_ _ 入海流。
在 Bert 的 Encoder 主导的时代,注意力是双向的,所以可以非常方便的填充中间 mask 的内容。
后来到了 GPT 的 Decoder only 的时代,token 只能从左往右生成,就没法填充中间的内容了。
然而填充中间内容的需求一直是存在的,比如有一段代码,想在函数名和函数体中间生成注释,这个时候按照 GPT 类似的 Decoder 的默认方法,就没填充,或者只能根据函数名进行填充。
OpenAI 的研究人员想了个好办法,在论文 《Efficient Training of Language Models to Fill in the Middle》中,提出了 Fill in the Middle 的方法。方法很简单,但是效果却异常的好。
其思想就是,既然没法改变 Decoder 的流程,那就改变数据的顺序。
比如“白日依山尽,黄河入海流”,采用 FIM 的方法进行训练的时候,可以表示成下面这样:
1 | |
这样的话,模型就可以根据 special token 来预测中间的“黄河” 两个字。其中 <Pre> 代表前缀,<SUF> 代表后缀,<MID> 表示中间填充的开始,<EOM> 表示中间填充的结束。
预测的时候只需要输入
1 | |
然后模型就会继续往后预测,直到遇到 <EOM> 符号。
OpenAI 同时发现,在预训练中引入这样的机制后,对于原来的模型性能几乎没有影响。
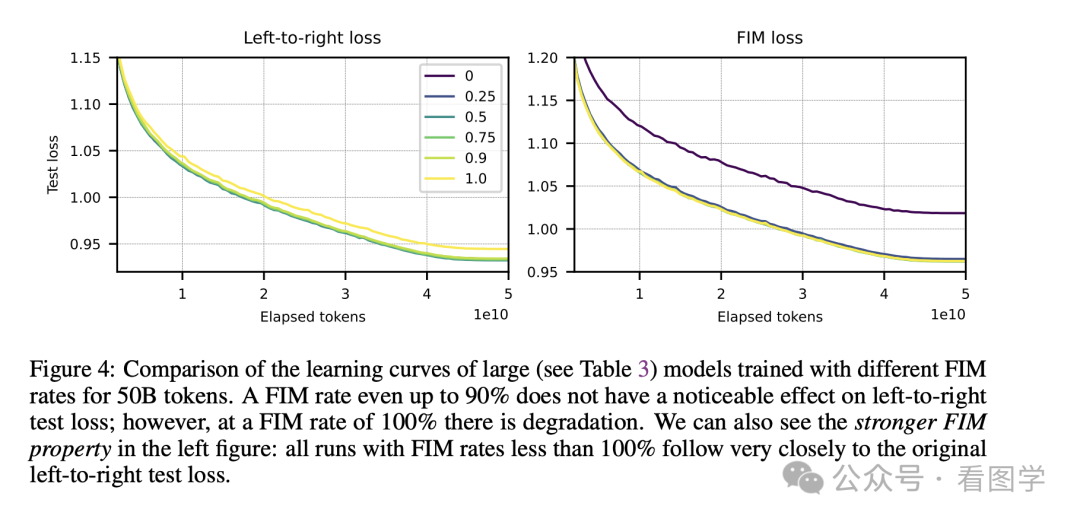
OpenAI 把这个现象称作 FIM-for-free property。
论文发出以后,基本上所有的 Code 相关的模型,都引入了这个机制。所以很多 copilot 调用的模型都具备中间代码补全的能力。
到了今天,基本上所有模型的预训练阶段都会加入 FIM。
百度大模型一面:“FIM (Fill in the Middle) 的原理是什么?有没有用过 Copilot?”
3.大模型推理 repetition penalty 是如何实现的?
大模型推理的时候,一般都有一个 repetition_penalty 的参数,看字面意思可以知道是加入了重复惩罚。但是具体是怎么实现的呢?
这个方法最早来源于 CTRL: A Conditional Transformer Language Model For Controllable Generation。
在 Sampling 那一章,作者提出了这么一个思路:
既然不想生成重复的内容,那就在预测下一个 token 的时候,让已经出现的 token 的预测概率变小就可以了。
用公式表达如下:
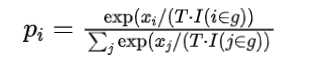
其中 I(c) =θ if c is True else 1, g 则是已经出现的 token。
θ 就是 repetition penalty 的大小。
也就是说,对于出现的 token,会让其 logits 变小。极限一点的话,可以让 input_ids 中的 token 再也没法出现。
具体实现也不难,代码如下:
1 | |
从代码可以清晰的看到,首先使用 torch.gather(scores, 1, input_ids) 获取到 input_ids 中的 logits,然后修改其 logits 的数值。
这里有个细节就是对于 小于 0 的数,是乘以 self.penalty, 否则是除以 self.penalty, 这样就让 input_ids 的 logits 统一都变小了,从而达到了避免重复的问题。
其他的参数比如 no_repeat_ngram_size,可以控制不重复的 ngram 长度,比如 no_repeat_ngram_size = 3, 就不会生成包含重复的 3-gram的序列。
但是需要注意,一旦总是出现那种不太正常的重复,比如无论怎么调节generate 的参数,输出总是一个词,这种情况大概率是模型用错了。
比如之前我测试某个模型,就因为使用了一个旧版本的 transformers,然后模型就一直重复,改成 trust_remote_code = True 就可以了。当然也可以升级 Transformers 库。
字节实习面试:“大模型推理 repetition penalty 是如何实现的?”
4.给一个 14B 的模型和 20B token 的数据,在 32张 A100 上要训练多少时间?
根据之前 OpenAI 的 Scaling Law 的论文,里面对 Transformers 的计算量进行了估算,大概的过程是这样的:
假设
- C 是训练的总 FLOPs (floating point operations)
- N 为模型的参数量
- D 为训练的 token 量。
Transformers 里绝大多数运输都是矩阵相乘,矩阵相乘的运算量是矩阵大小的两倍,因为对于矩阵中的每个元素来说,需要一次乘法和一次加法。
先说前向运算,每一个 token 都会在模型里运算一遍,所以对于一个 token 来说,前向运算的 FLOPs 为 2N。
那么对于 D 个 token 来说,前向运算的 FLOPs 为 2ND。
而神经网络的反向传播的 FLOPs 量,大致为前向运算的 2倍,共计 4ND。原理可以看:学妹问:“反向传播的计算量是前向传播计算量的几倍?”
所以,最终 C = 6ND。
当然这只是个大概的估计,实际上运算量会更多一些,因为还有一些非矩阵的运算。如果为了节省显存,采用了一些比如 Activation recomputation 等,计算量会显著增加。
知道了总的运算量,下一步就是查一下显卡的运算速度,就能得出题目的答案。
对于 A100 来说,FP16 的峰值运算速度为 312 TFLOPS (Tera Floating Point Operations Per Second), 也就是 $312\times10^{12}$
那么对于前面的任务来说,需要的时间为
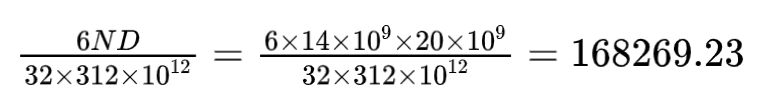
上面的单位是秒,换算成天为 1.95 天。
但是注意这里只是最理想的情况下,实际上运算量比这个大,而且对于大模型的训练来说,根本无法达到 A100 的峰值运算速度,因为有大量的通信,而且内部运算也并不全是 FP16 的计算。
我们看看 llama 当时的训练数据:
When training a 65B-parameter model, our code processes around 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. This means that training over our dataset containing 1.4T tokens takes approximately 21 days.
带入上面的公式:
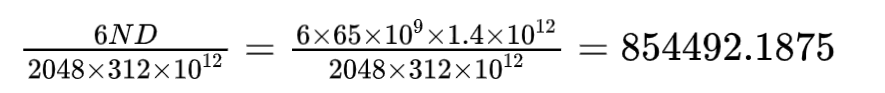
换算成天数为 9.89 天,但是实际上用了 21 天。从这里可以推断出,他们的 GPU 的平均运算速度为 146.94 TFLOPS, MFU(Model FLOPs Utilization, 算力的利用率)为 47.1%
而且模型越大,MFU 越低,比如 Llama 3 405B的训练数据如下图, 最高的 MFU 也就 43%:
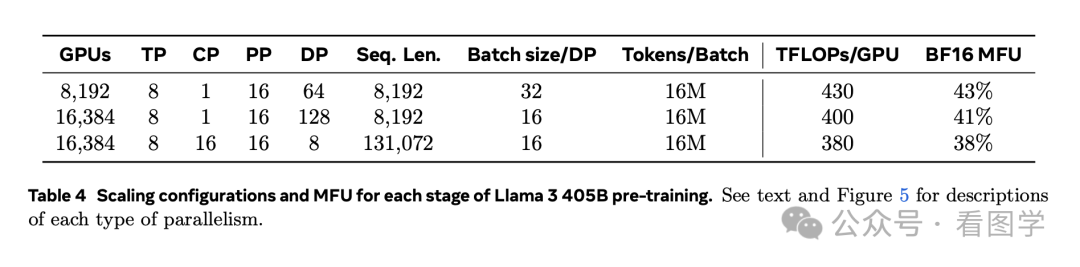
这已经是业界几乎最顶尖的水平了。
所以我们按照业界的顶尖水平来估算的话,最开始问题的答案修正为 4.135 天。
小米一面:“给一个 14B 的模型和 20B token 的数据,在 32张 A100 上要训练多少时间?”
5. 手撕 MHA,阿里的一面问的真是太细了
这个在面试的时候经常会问到, 但是涉及到的细节比较多。
核心的代码其实并不多,下面结合代码来说一下。
代码大概 10 行,实际 11行。10行也不是不行,但是为了可读性,还是11行把。
首先,要将输入 x 做3个线性映射得到 QKV
1 | |
因为要实现 multi attention, 所以要将最后一维切割。比如本来是 (4, 512, 128) 大小的矩阵, 现在有 8个头, 最后一维被切成8块, 变成了 一个 (4, 512, 8, 16) 的矩阵。
但是现在序列长度 512在矩阵的位置是第二位, 我们要保持 512 这一维和 16 这一维在一起,然后做 attention, 所以还需要做一个 view 的变换, 代码如下
1 | |
接下来就可以求 attention 的分数了
1 | |
注意这里要除以根号d, 至于为什么,可以看:NLP面试官:“Attention为什么要除以根号d” 算法女生这么回答当场想发 offer
得到 attention 之后, 我们还需要对得分进行 mask, 因为当前位置不应该看到后面的信息。
1 | |
这个 self.bias 是一个 tril 矩阵。右上角全为 0。
得到分数后, 就可以和 v 相乘了, 并且还原到多头前的维度。
1 | |
上面代码的最后是再一次做了个线性变换, 至此 MHA 算是写完了。
当然只是最基础版本的 MHA, 现在 flash attention 也已经是标配,如果在面试过程中你说我会写 flash attention, 那绝对是大大的加分项。
但是写 flash attention 有点难度,大概要 100 行,可以参考这个:
https://github.com/tspeterkim/flash-attention-minimal/blob/main/flash.cu
6. 大模型推理的时候 top k 和 top p 同时设置的时候怎么采样?
这个题目就是考察细节, 直接从 transformers 的源代码中找答案即可。
其实在 transformers 的4.41.x 版本之前, 在 src/transformers/generation_utils.py 中专门有段 topk 和 topp 的处理代码,写的很简洁, 如下
1 | |
从这个函数中可以清晰的看到, 是先 topk 然后再进行 top p 的。
先进行 topk 的处理, 选出最大的 k 个 logits, 然后剩余的 logits 值都设置为负无穷, 这样 softmax 的时候概率就变成 0 了。
然后在这 top k 个 logits 中,计算累计概率, 选出符合条件的 top p 个 logits。
我之前在自己写一些调试代码的时候,经常 import 这段代码。但这随着版本更新, 发现这个函数没了。
这一段逻辑跑到了 src/transformers/generation/utils.py 中, 如下所示
1 | |
可以看到处理的顺序还是没变, 只不过变成了 TopKLogitsWarper 和 TopPLogitsWarper。
很多代码往往越写越复杂, 封装的越来越多, 比如 langchain, 个人感觉就封装的略有点过头了。
大模型推理的时候 top k 和 top p 同时设置的时候怎么采样?
7. 给一些 token id 和 对应的 tokenizer, 可以将其无损的还原为原始文本么?
需要看 tokenizer 的实现算法, 如果 tokenizer 是采用类似 Byte-level BPE 的算法, 就可以做到无损还原。
这是因为 Byte-level 的 BPE 算法在构建 token 的时候, 完全是基于字节来统计的, 所以其可以对任意的数据进行 encode, 不只是局限于文本数据。
举一个具体的例子可能更好理解。比如下面这句话:
stay foolish stay hungry
如果是 word 粒度的 tokenize 方法, 那处理的对象是 word, 那第一步可能先把 stay 给变成 token, 因为 stay 出现了2次。
如果是 char 粒度的, 那处理的力度就是字母, 那会先把 st, ta, y_, oo 先变成 token。
非 Byte level 的, 总是基于现有文本元素来进行组合。比如英文就是 26 个大小写字母还有其他标点等符号, 中文则是汉字。
这样做总是会存在一个 Out Of Vocabulary 的问题, 比如现在有个单词, clever, 那就没法表示了, 只能用一个统一的token 来表示。
那自然英文的 tokenizer 就没法给中文做 tokenzier。
Byte-level 是怎么做的呢?处理的对象是字节。不管是什么语言,最终在计算机里都是二进制的数据。
比如单词 stay 在计算机里表示如下:
- s: 01110011 (0x73)
- t: 01110100 (0x74)
- a: 01100001 (0x61)
- y: 01111001 (0x79)
在训练 tokenize 模型的时候, 直接统计字节的 pair. 比如 (0x74, 0x74) 出现次数最多, 则优先变成 token。
由于所有的数据都是由字节组成的,而初始的 token 只需要 256 个, 就覆盖了所有的可能, 所以完全没有 OOV 的问题。
比如汉字是由 Unicode 的组成的, 比如“看图学”这三个字, 用 Unicode 的十六进制表示为
- 看:0x770B
- 图:0x56FE
- 学:0x5B66
Byte level 的不管原始的信息是什么,就是直接用字节组合。
所以这个时候, 英文的 tokenizer 也可以给汉字编码, 因为汉字也可以表示成字节。
比如 llama 2 的词表里大概有5k 多个汉字, 其他不在词表里的汉字,可能需要3-5个 token 来表示一个汉字, 这就造成了吞吐效率的极大浪费,所以需要加入新的词表对 llama 进行 post pretrain 才行。
比如你问 llama2 问题, 对于输入的中文还是可以理解的,但是输出的时候还是倾向于用英文来输出。如下图所示:

给一些 token id 和 对应的 tokenizer, 可以将其无损的还原为原始文本么?
8. 为什么 Attention 最后采用了 Dot Product 而不是 Addition?
在 Attention 刚被提出来的时候,其实是通过 Addition 来建立关联关系的。在 Bahdanau Attention (Bahdanau et al., 2014) 中, 表示为
$$
e_{ij}=V_a^T\tanh(W_as_{i-1}+U_ah_j)=V_a^T\tanh(Q+K)
$$
后来, Luong Attention (Luong et al., 2015) 对比了多种 Attention 的方式, 其中就包括了 Transformers 最终采用的 dot attention, 表示为:
$$
e_{ij}=W_Qs_{i-1}(W_Kh_j)^T=QK^T
$$
在论文中, 作者提到 Addition Attention 在他们的实验里的效果并不太好。
在 《Attention is All your Need》 的论文中, 作者提到:
“While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since **it can be implemented using highly optimized matrix multiplication code.**”
所以说无论是效果还是计算效率上, dot attention 似乎都更好一点。
那么计算效率到底快多少呢?
在论文《Data Movement Is All You Need: A Case Study On Optimizing Transformers》 的文中, 作者对比了 BERT 中不同运算的耗时。如下表:

其中三角形 △ 代表的是矩阵相乘, 方块 ◻️ 代表的是 softmax and layer normalization, 圆形 ○ 则是剩余的运算,比如 biases, dropout, activations, and residual connections。
可以看到, **非矩阵相乘的运算量只占了 0.2%, 但是耗时却占据了 39%**。
之所以差异如此明显, 是因为 Nvidia 的显卡里专门设置了 Tensor Core, 和其他运算模块的对比如下:

可以看出,差距还是很明显的。FP32 使用 Tensor Core 计算的 TFLOPS 是普通 FP32 模块的 156/19.5= 8 倍!
在这个疯狂 Scaling 的时代, dot-product attention 似乎也就成为了唯一的选择。
“为什么 Attention 最后采用了 Dot Product 而不是 Addition?” 字节一面问的好细
9. 机器学习的三要素是什么?
现在网络上众说纷纭,大概有几种说法:
- 模型+策略+算法。来源:《统计学习方法》
- 数据+模型+算法。
- 数据+特征+算法。
- 表示+评估+优化。来源:Domingos 2012 《A few useful things to know about machine learning》
- 表示+策略+优化。
这几种说法中,1和4是更为确切的。2,3略有欠缺,缺少了评估这一环节。5是1和4的另一种说法。
巧合的是,李航老师和Domingos教授都是2012年提出来的概念,可以说是英雄所见略同了。
李航老师所说的模型(Model),Domingos 教授所说的表示(Representation),说的都是把数据和模型参数映射到学习的假设空间(hypothesis space),更朴素一点的说法可能是建模。数据、特征、要训练的模型其实都是表示的一部分。
李航老师所说的策略(Strategy),Domingos教授所说的评估(Evaluation),说的都是要构造一个损失函数或者评价函数,来评价表示/模型的好坏。
李航老师所说的算法(Algorithm),Domingos教授所说的优化(Optimization),说的都是损失函数的优化算法。借助于损失函数在假设空间中找到问题最优的解。
整体来说,Domingos 教授的表述更宏观一些,李航老师的更接地气一些。
如下图所示:
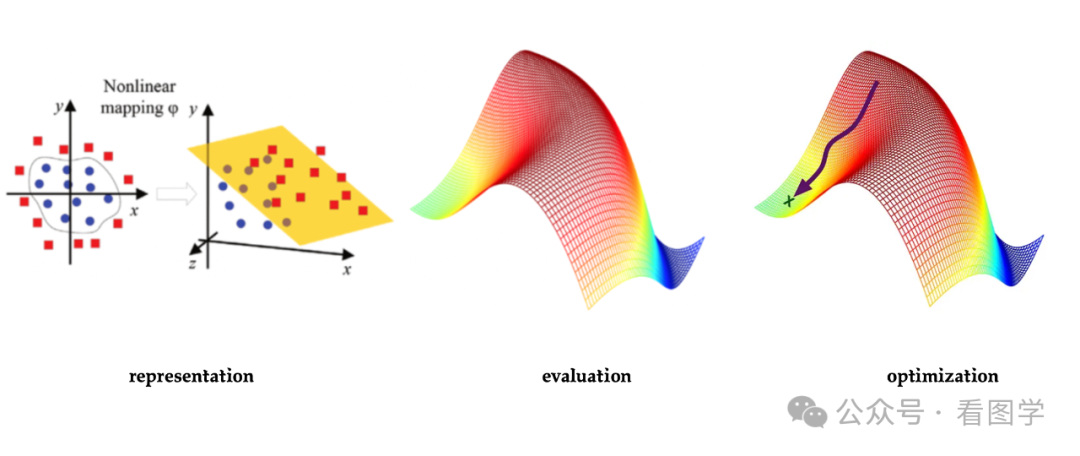
需要注意的是,三要素之间不是任意可以组合的,模型适用的损失函数和优化方法都又一些原理蕴含其中。下图列举了一些常见三要素的组合关系

10. 大模型训练为什么用梯度下降,而不是收敛更快的牛顿法?
梯度下降是基于泰勒展开一阶偏微分的优化方法, 而牛顿法则是基于泰勒展开二阶偏微分的方法。
理论上牛顿法的收敛速度要比梯度下降要快的多,那为什么大模型和机器学习都采用梯度下降这种比较慢的优化方法呢?
原因有三:
性能问题
从迭代的次数来看, 牛顿法确实需要更少的迭代次数, 因为牛顿法是直接算出下一个极值点在哪里。但是梯度下降则是一步一步的逼近, 尤其是在接近最小值的时候, 梯度往往越来越小, 迭代也越来越慢,所以在梯度下降的 loss 刚开始下降很快,后面则趋于平缓。用牛顿法的话, loss 则陡峭的多, 如下图所示, 牛顿在第4次的时候就可以停止了:
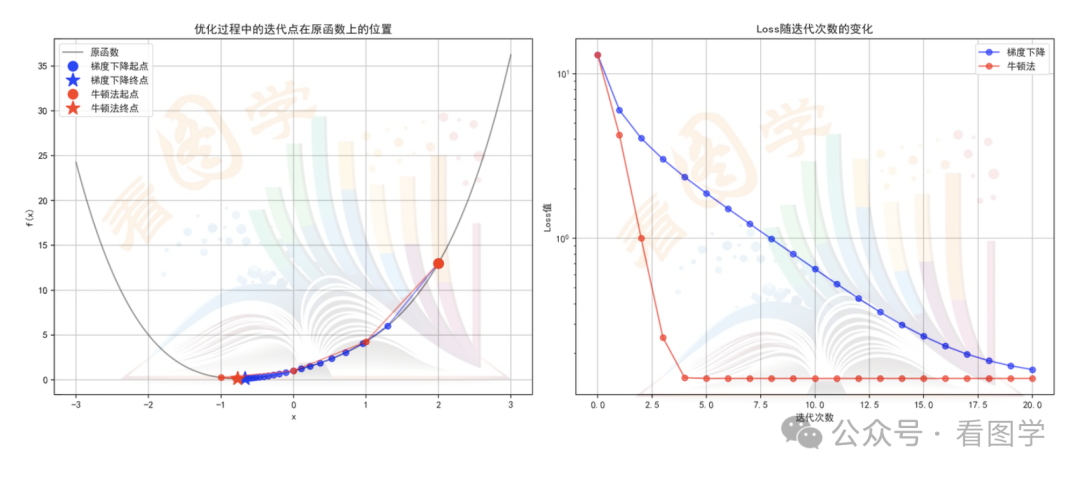
但是也不能光看迭代次数, 还得看每次迭代的时间复杂度。
对于梯度下降来说, 每次迭代的时间复杂度是 O(N), 其中 N 是参数量, 是线性的。
但是对于牛顿迭代来说, 由于要计算 Hessian 矩阵, 时间复杂度是 O(N2), 更糟糕的是, 牛顿法需要计算 Hessian 矩阵的逆, 时间复杂度一下子变成了 O(N3).
所以当参数规模较小的时候, 牛顿法确实会更快。但是当模型参数量很大的时候,牛顿法虽然总迭代次数少,但是每一步的时间复杂度很高, 最终的结果反而更慢。
收敛稳定性问题
牛顿法对于初始值的选择尤为敏感。如果刚开始就选择在了某个维度比较平坦的地方, 也就是二阶导数接近 0 的地方, 由于要求二阶导数的倒数, 计算出的下一个位置会和当前位置非常远, 由于泰勒展开的二阶近似只在局部有效, 此时牛顿法的精确性已经失去了, 所以优化过程很容易就发散了。
当然可以通过加入一些阻尼来限制更新的不要太剧烈, 但是加入阻尼有时候反而丧失了牛顿收敛快的特性。
鞍点问题
相对来说, 梯度下降比起牛顿更容易脱离鞍点区域, 因为鞍点就是牛顿法的一个解, 到了鞍点牛顿法就认为已经完成优化了。
而梯度下降总是有个步长, 虽然在鞍点附近走的很慢,但是还是有机会走出来的。除非恰好就在某一个维度的鞍点上来回震荡, 这个时候可能需要加入点随机扰动才能走出鞍点。
牛顿法的优化
虽然直接用牛顿法优化不太可行,但是这么多年来也有很多算法借鉴了牛顿法的二阶优化的思想。
比如拟牛顿法 BFGS和L-BFGS, 而现在流行的一些基于动量的优化器, 比如 Adam中的二阶矩项(momentum term),个人感觉其实就是在近似二阶Hessian信息,或者至少是在近似其对角线元素。这种近似使得Adam能够在保持计算效率的同时,捕获一定的二阶优化信息。
大模型训练为什么用梯度下降,而不是收敛更快的牛顿法?阿里二面问的好有难度
11.如何评估大模型的性能?目前的评估方法都有什么?
关于如何系统的评估一个大模型,之前微软有一篇综述写的很好,而且有中文版,可以直接点击下面网页查看:
https://www.microsoft.com/en-us/research/articles/evaluation-of-large-language-models/
但是,这些传统的测评方法目前都面临着一些问题。下面稍微列举几点:
数据污染造成的刷榜问题
由于大多数测试集合都是开源的,很容易通过合成数据来构造一批类似的样本。这都报速成班了,那结果自然很不错。
这种刷榜怎么识别呢?比较简单的方法就是用新的数据去检测,比如每年新出的高考题,之前肯定谁都没见过,在这些题目上做的好,才是真的好。
当前的测评数据已经落后于模型的真正性能
现在的模型已经逐渐能解决越来越复杂的问题,比如 GPT o1, 而这些传统的测试集合往往都比较简单,并不能测试出模型的真正能力。
王自如困境
除了开源的一些测评,业内也有一些野榜混淆视听。
毕竟搞测评也得花钱,团队里的人也得发工资,现在有人赞助测评机构了,把人家的排名弄的很低,好意思么?
所以很多野榜都很难保证公平性。
目前唯一可信的测评榜单
目前没办法刷榜的就是 Chatbot Arena 了。这个排行是让大模型随机匹配对手打天梯。
然后背后有一套积分系统,应该是 Elo 评分系统。随机让两个模型对相同的输入生产答案,然后让人盲评这两个模型的好坏。
当模型击败一个积分更高的模型时,得分会提升,反之则会下降。就这样最后所有的模型都有一个积分,就可以看出每个模型的好坏。
但是这个评测有一点需要注意,那就是一个刚进入系统的新模型,可能会因为对战的数据不足导致测评结果有偏差。比如 Claude 2 刚进系统的时候,评分要比 Claude 1 要低,但是随着对战次数的增加,效果就越来越好了。
然后这个榜单还有一些细分选项,比如 Style-controlled ranking。让模型生成一些有约束的风格,比如长度,格式等。这时每个模型等排名会发生变化,也挺有意思。
12.Transformers 为什么采用 QKV Attention?
Transformers 的论文在讲述 Attention 这一部分时并没有讲的特别细,尤其是关于 Query, Key 和 Value 的设计似乎是突然就水灵灵的出现了。而且最终的形式比以往的 Attention 都要简略很多。
在论文中没有找到答案,那只能看看同时期的论文有没有类似的研究。最终在一篇《Frustratingly Short Attention Spans In Neural Language Modeling》的论文找到了类似的结构。我们来看看这篇文章时怎么说的。
这篇论文是基于最早的 Bahdanau Attention (Bahdanau et al., 2014) 进行改进的。

这篇论文认为当时的 Attention , 隐向量至少承担了3个功能:
- 计算 attention score
- 计算 context vector
- 作为 hidden state 来进行 RNN 的计算。
这一个向量的任务实在有些繁重。为了更好的适配任务,作者参考了 Memory Netorkds,一次输出了 3个 隐向量, 一个是 key, 一个是 value,还有一个是 predict。这3个隐向量来计算 Attention, 功能如下:
- key 用来计算 attention score.
- value 用来和 Atention score 相乘。
- predict 用于预测词的分布。
其中 predict 可以先不管。公式如下
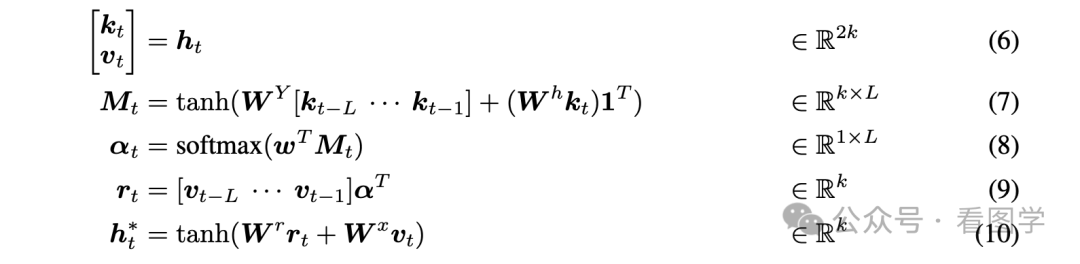
看公式就可以知道,value 在这里作用和 Transformers 中的 Attention 的 value 是完全一致的。
那怎么没有 query 呢?实际上 query 被隐藏在了 key 之中。在那个 Attention is all your need 之前的时代, Attention 和 RNN 依然是深度绑定的。
作者在这里用了时刻 t 的 key 向量,和时刻 t 之前的 key 向量做了 Attention,因为作者假设时刻 t 之前的 key 和 value 是 Memory。
所以 query 就是 k_t, 而 t 时刻前面的就是 key。
虽然写法不一样,但是 Transformers 的 qkv Attention 的设计和这篇论文的设计的整体框架是一样的。细微之处的不同点列举如下:
- Transformers 由于丢弃了 RNN,所以可以更好的并行,采用了矩阵运算的形式。
- Transformers 采用了 dot Attention,应该是参考了 Luong Attention。而这篇文章依然采用了 Bahdanau Attention 所使用的 Addition Attention
- Transformers 的 Attention 是全连接图,而这里是 causal 形式的 Attention。
虽然原始论文没有细说,但是这应该就是 qkv Attention 的由来的一个解释。
“Transformers 为什么采用 QKV Attention?” 大模型面经
13. Attention 为什么使用 Multi Head ?
Multi Head Attention 最早可以追溯到 《A STRUCTURED SELF-ATTENTIVE SENTENCE EMBEDDING》 (Lin et al., 2017) 这篇论文。
从题目就可以看出,是用 Multi Head Attention 来做表示学习。
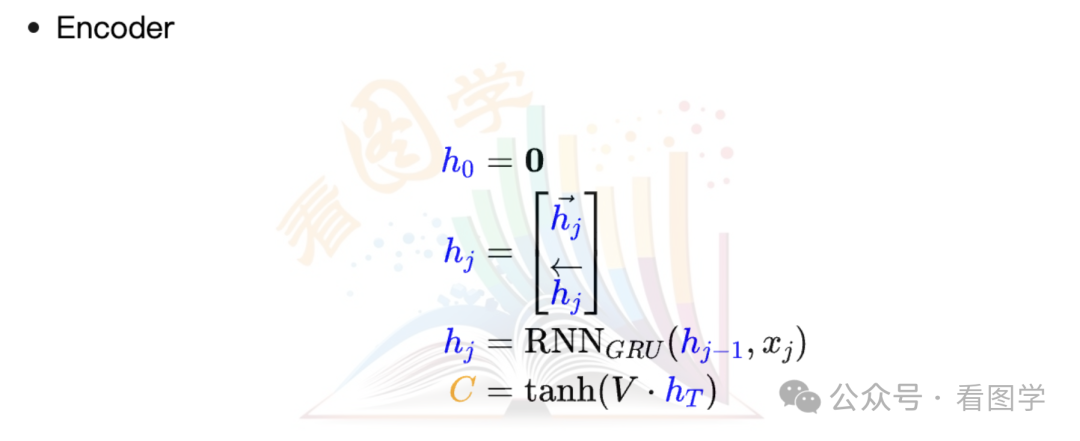
作者参考了 Bahdanau Attention, 只不过在计算 attention score 的时候,输入从 $h_j$、$s_i$改成了双向 LSTM 的两个方向的 hidden states。
- Encoder

从公式明显可以看出,Self Attention 计算 Score 的设计明显是参考了 Bahdanau Attention 的计算方法。
上面的计算是单个 Attention 的计算方法。然后借鉴一下卷积网络的多个 kernel 的思想,作者设计了多个 Attention,期望不同的 Attention 学习到不同的注意力,从而更好的提取特征。这种一个不行就上多个到方法在深度学习中经常使用,比如 CNN 多 kernel, MultiHead Attention, Mixture of Experts 等。
基于这个思路,作者提出了 Attention 的矩阵运算形式。

这其实就是MultiHead 了,在公式中是通过 r来体现的。
然后这个矩阵相乘 AH已经和 Transformers 最终形态的 Attention$AV=\text{softmax}(\frac{QK^\top}{\sqrt{d}})V$
有点类似了。
文中也对比了随着 head 数量增多后,在具体任务上的表现,如下图所示:
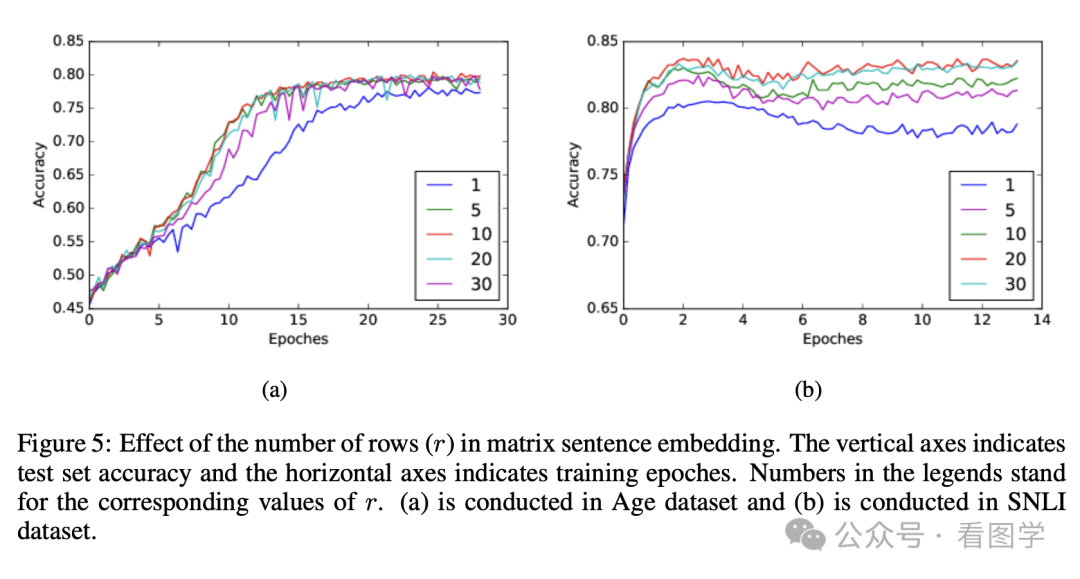
后来又有学者认为,当前的 MHA 的形式,同一层的 Head 之间没有任何关联,想建立关联得到下一层了,这样的效果可能不如多层的 Single Head。然后做了一些实验,也确实证明了多层 Single Head 比浅层的 MHA 效果好,具体见《https://arxiv.org/pdf/2106.09650》。
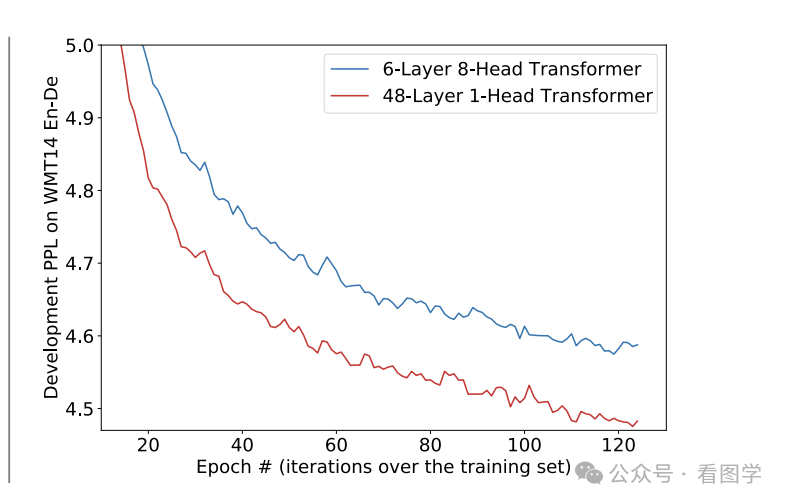
那为什么没有流行起来呢?核心还是 MHA 可以非常方便的并行计算,而采用 Single Head 的话,层与层之间有诸多的非线性操作还有 norm 等,不如 MHA 直接做一些视图变换然后直接矩阵相乘效率高。
14. 为什么 LLM 推理时通常采用 left padding?
其实在几年前,NLP 的大部分任务都是 right padding 的,因为哪个时候 Encoder 的架构是主流。
现在的 tokenizer 都会提供 padding 操作,但是当采用 right padding 做tokenize,然后用现在的大模型推理的时候,就会得到如下的警告:
1 | |
原因就是目前的大模型基本清一色都是 Decoder Only 的架构,当采用 left padding 的时候,一个 batch 内的所有样本预测的就恰好是下一个词。
举一个例子,对于一个 tensor
1 | |
如果采用 0 作为 pad_id, 则 padding 后为
1 | |
这个时候预测的下一个 token 直接拼接上就行。
如果采用 right padding, 则需要进行特殊处理。right padding 后为
1 | |
这个时候第一个样本显然不能从最后的位置开始预测,而是要从3后面的位置开始推理。
所以对于不等长的输入,right padding 要从最短的序列位置开始推理。
但是对于其他样本来说,其实是不需要预测的,因为本来就是输入,但是机制问题,必须要从最短的位置开始预测。其他的样本在哪些不需要预测的位置,其实也预测了,但是把结果丢掉了,这就造成计算资源的浪费。
最早 llama 发布的时候,就给出了通过 right padding 来进行预测的代码,可以清晰的看到其流程如上所述。

那又有人问了,为什么要做 padding?哪些填充的字符不也是白白占了显存和计算资源?串行计算可不可以?
padding 却是会占用一部分,但是因为 GPU 针对矩阵运算有加速,所以带来的加速效果是远超扔掉 padding 然后串行的。
这个道理就跟 causal attention 计算的时候,明明有一半的 score 不需要计算,但是仍旧采用先算完然后在 mask 的位置 fill zero 是一样的道理。
“现在大模型为什么都用 left padding?” 字节实习一面,学姐的面经
15. ROC-AUC 的值代表了什么?
这个问题其实完全可以通过数学来推算出来,这里先说结论:
AUC的值,就是从样本中任意取一个正例和一个负例,分类器给正例的得分大于给负例得分的概率。
下面是详细的证明:
如果把ROC曲线看成是TPR对FPR的函数,TPR=F(x)。我们对这个函数进行积分。如下图所示:

则有
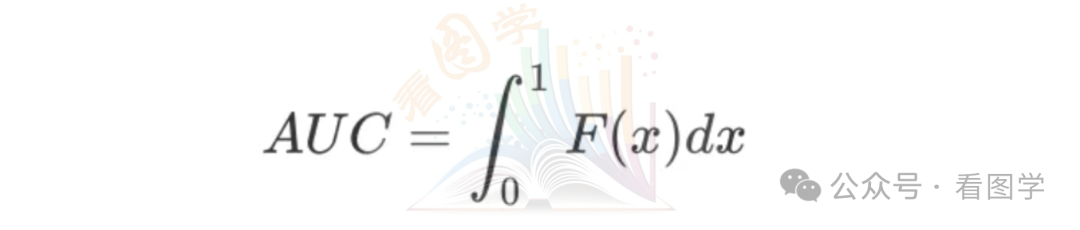
假设样本label为y,模型预测得分为s,阈值为t,正例的概率密度函数为 (图中红色部分),负例的概率密度函数为 (图中蓝色部分).则有
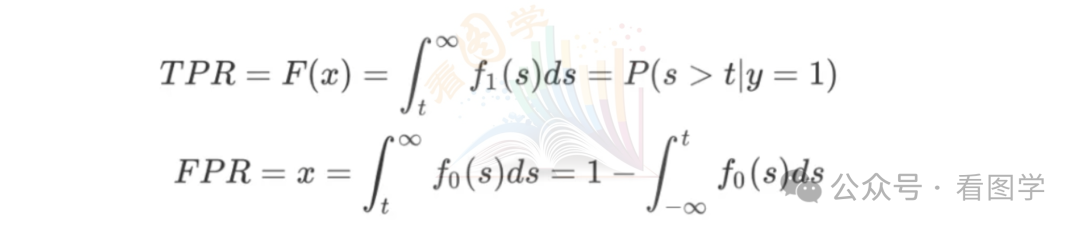
这两个公式就对应之前 TPR 和 FPR 的计算公式。
其实就是下面两个动图。


从公式上可以看出,x是t的积分上限函数,根据积分上限函数的性质,得到:
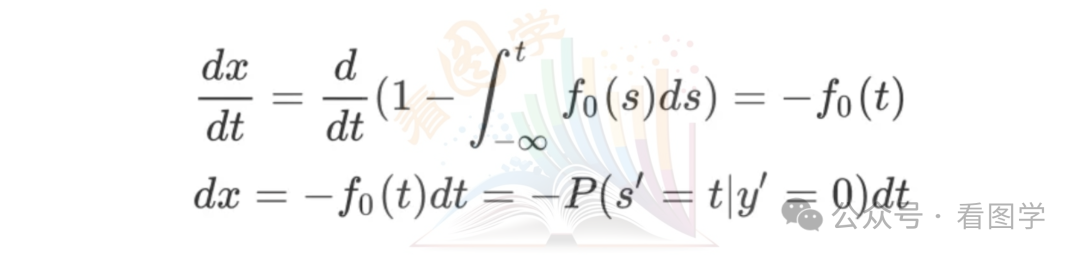
带入 AUC 的公式,则有
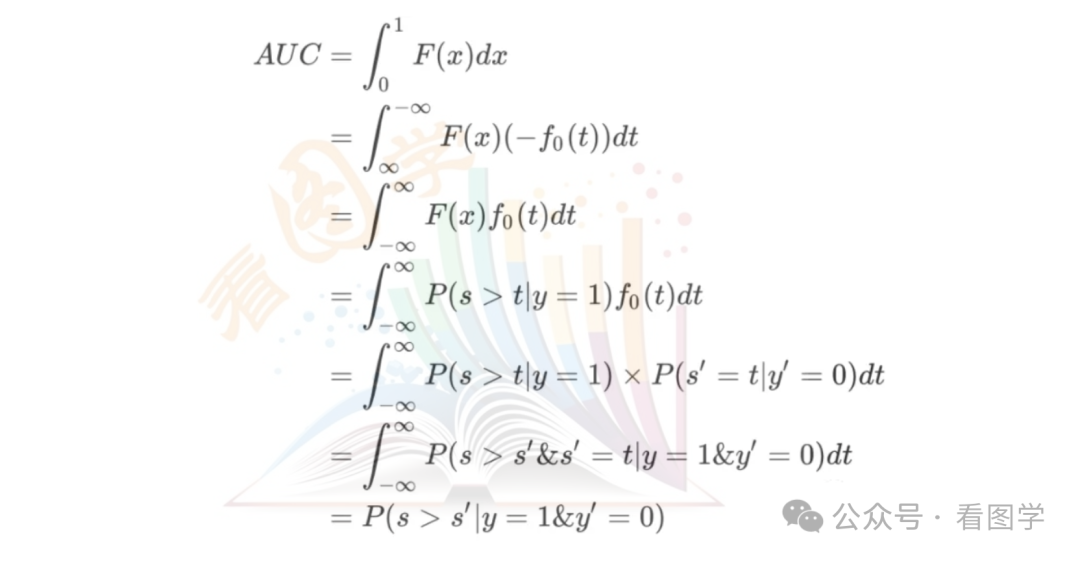
上面推导需要解释一下:
第二行,因为FPR的取值范围从0到1,对应着阈值是从大到小的变化。可以从动图中看出,只不过动图中阈值是从小到大,FPR是从1到0
第五行, 的含义就是该样本为负例,得分为t的概率。加引号是为了和正例区分。
第七行,该积分相当于是遍历阈值t,同时负例得分和t相同,也就是负例遍历所有可能的得分情况。
所以最终得到这么一个结论:AUC的值,就是从样本中任意取一个正例和一个负例,分类器给正例得分大于负例得分的概率。
正因为这个性质,AUC 在推荐排序中也经常使用。
16. ROC-AUC 曲线是什么?怎么计算?
先看两个图,来感受一下 ROC 到底是啥。如果看不明白,后面有解释。

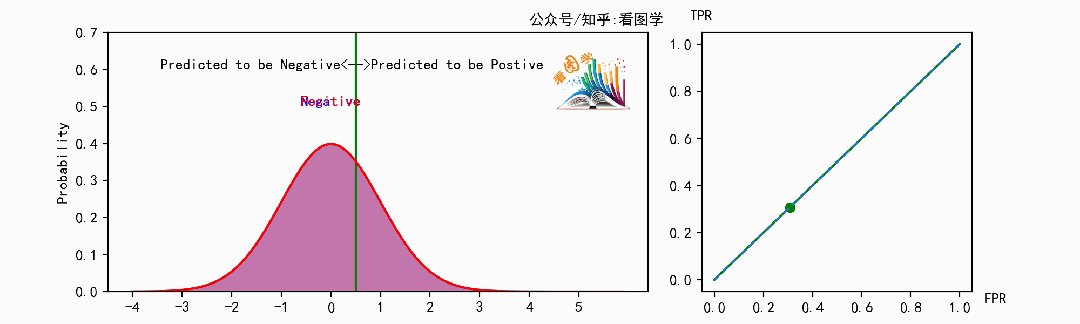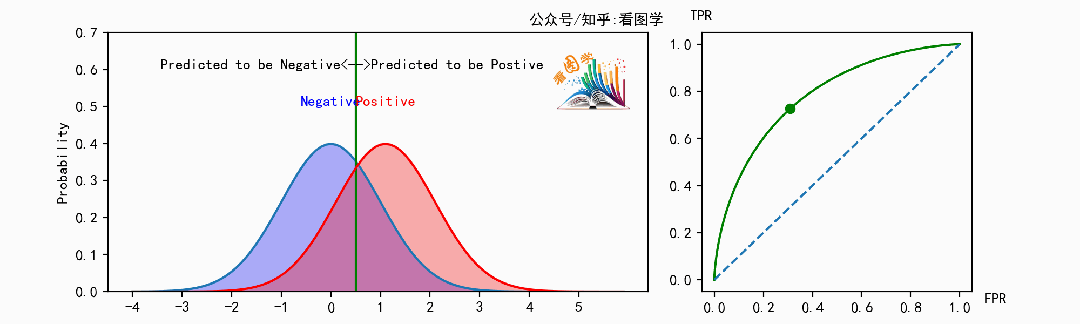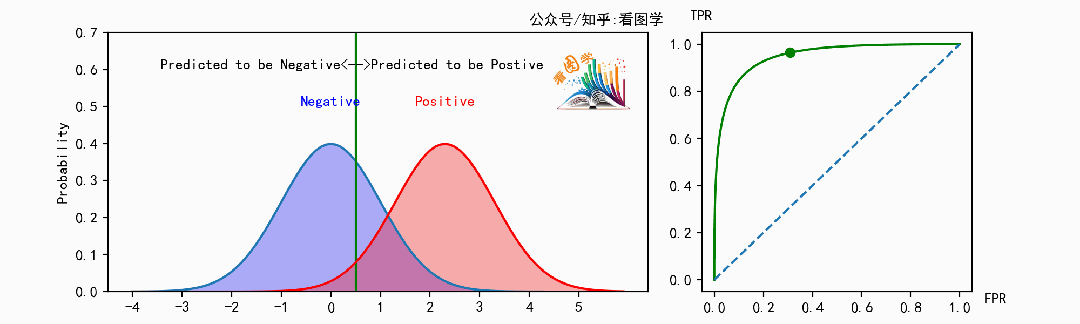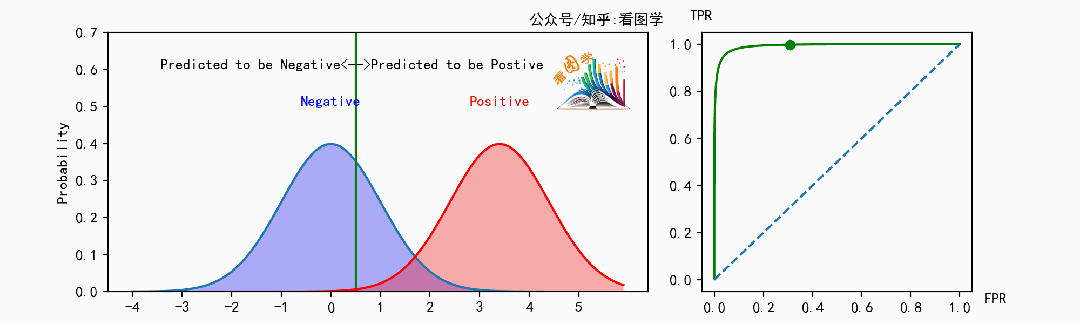
ROC曲线(Receiver operating characteristic curve) 最早用在雷达系统中,前面单词中所谓Receiver就是雷达接收器。后来又广泛应用在医学领域,然后又在数据统计和机器学习中担任了重要角色。
雷达的操作员(Radar operator)也是花钱雇的,那不得打个绩效。ROC 就相当于雷达操作员的绩效,用来衡量雷达操作员的识别能力。
根据雷达的波形,操作员会判断是否出现敌机,当时正处于二战时期,主要就是来识别是不是日本的战斗机。
如果日本的战斗机真的飞过来了:
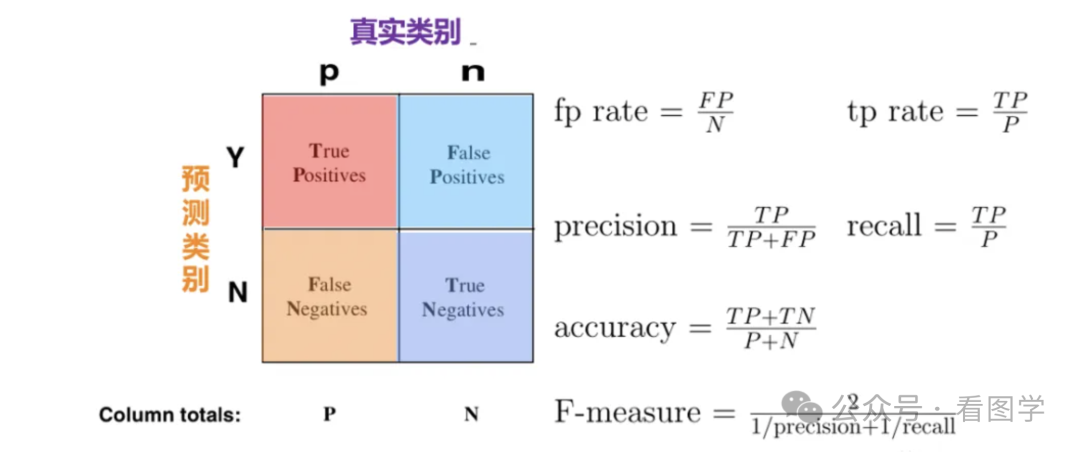
- 操作员判断是真的飞过来了,此时叫做:正例预测对(**True Positive)**,有时也叫真阳性。
- 否则叫做:正例预测错(False Negtative),有时候也叫假阴性。
如果日本的战斗机没有飞过来:
- 操作员判断战斗机没飞过来,此时叫做:负例预测对(True Negative), 有时候也叫真阴性。
- 否则叫做:负例预测错(False Positive),有时候也叫假阳性。
做成图像如下:
那么怎么给操作员打绩效呢?当时的科学家们提出了两个概念:
TPR(True Positive Rate),表示操作员从真正的战斗机中识别出的比例,一个更常用的名称叫召回率。
FPR(False Positive Rate), 表示操作员在没有战斗机的事件中误报的比例。
这两个指标的计算公式见上图。
然后以 FPR 为横坐标,以 TPR 为纵坐标,在对应位置打一个点,就是这个操作员实际能力的可视化。
比如有5个操作员打的点如下图:

在这个图里面,我们肯定是希望 误判(FPR) 越小越好,召回(TPR) 越大越好,所以 D > B > C
A 和 B 各有千秋,没法硬比。D 实际上是整个图里的最优点。
还有一点需要注意的就是,虚线代表了随机猜测。因为当我们随机猜测为正的概率为 p 时, 假设 N 个正例,M 个负例。
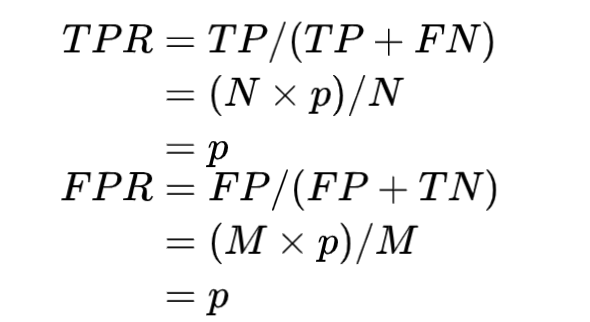
所以当点落到虚线上时,就代表了随机猜测。而 TPR > FPR 则代表了比随机猜测要好,否则则比随机猜测还差。
前面几个指标,比如 Accuracy, Precision, Recall 等,当 TPR = FPR + δ 时,只要 δ > 0, 都会变大。具体的证明只需要带入公式计算就可以了,这里不再赘述。
当操作员每次的输出是一个概率时
之前操作员要么判对,要么判错,在二位平面上就一个点。
但是有时候操作员也拿不准,输出一个概率时,我们可以自己设置阈值来把操作员的每个 (FPR, TPR) 点画出来, 此时就得到了一条 ROC 曲线。
计算如下,左图的区域闪烁对应同样闪烁的右侧的公式部分。

TPR 可视化
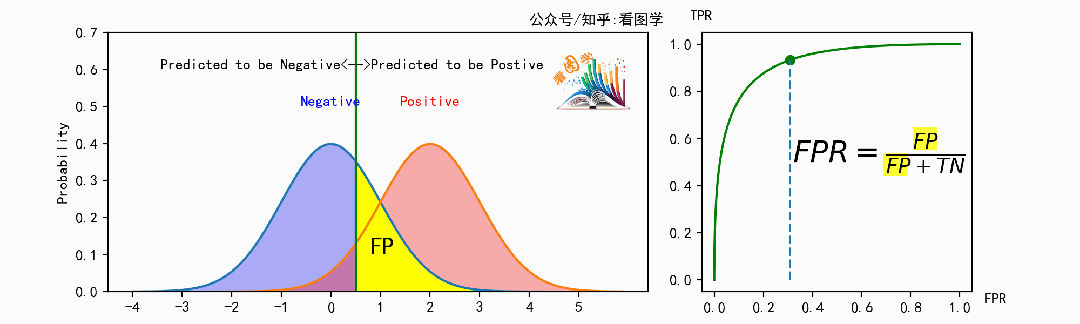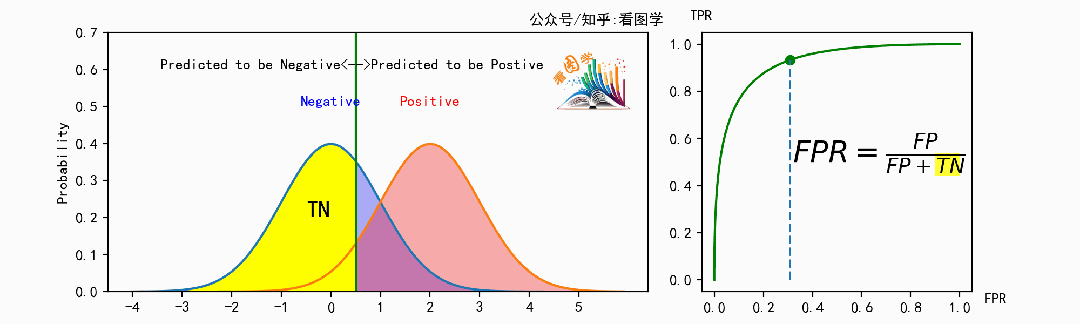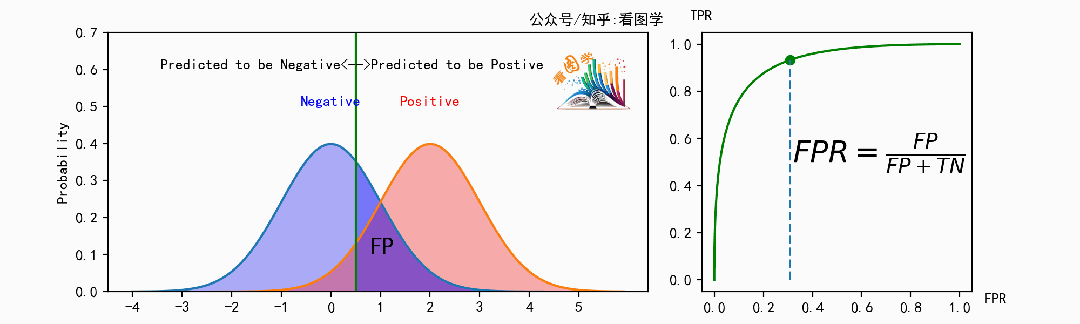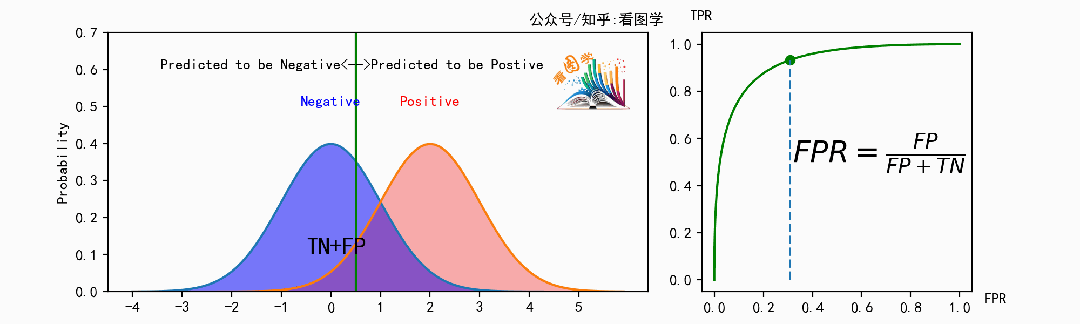
FPR 可视化
当遍历阈值(移动的竖线)时,即可得到ROC曲线。如下图:
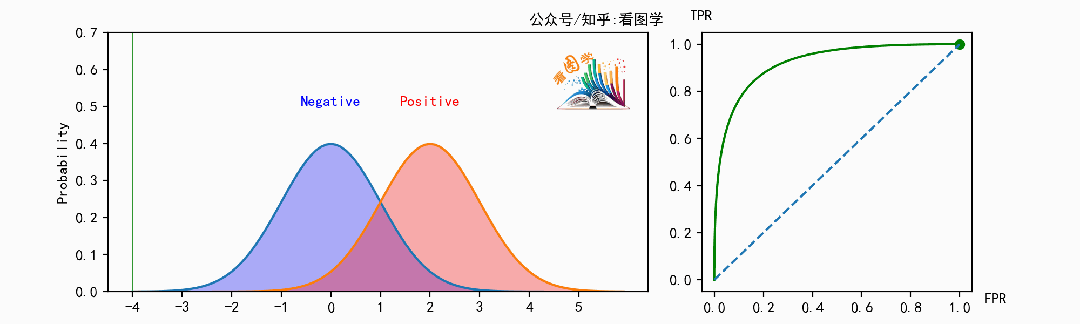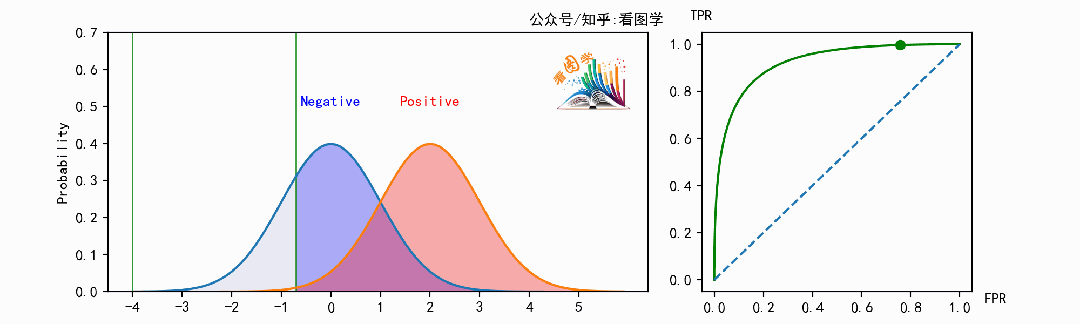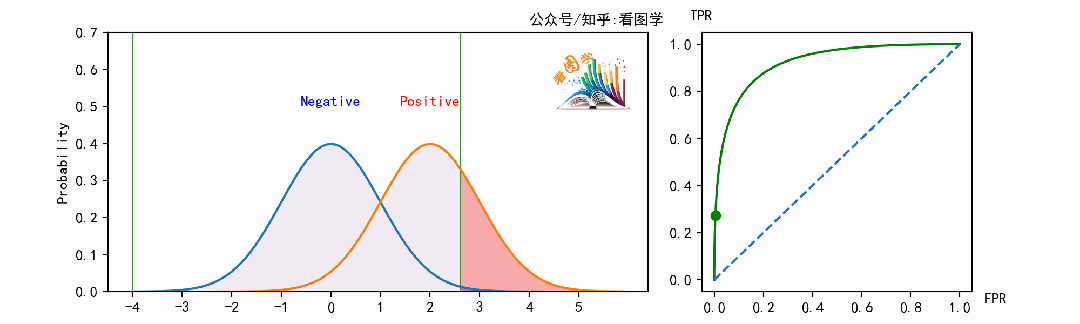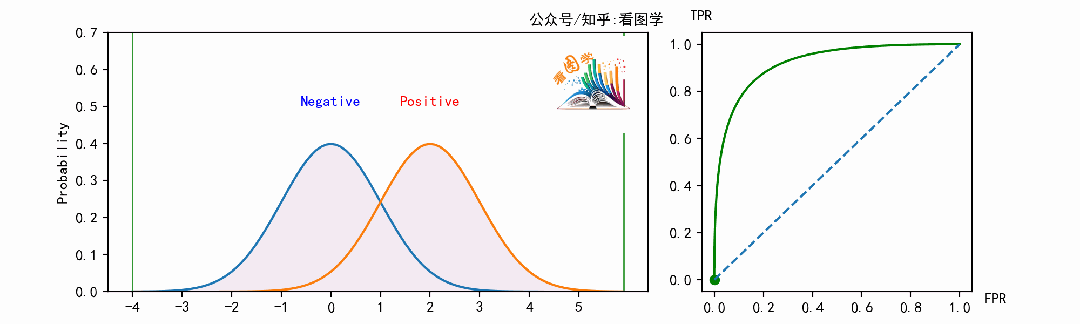
下面是当分类器的能力变得越来越好时,ROC 曲线的变化情况:
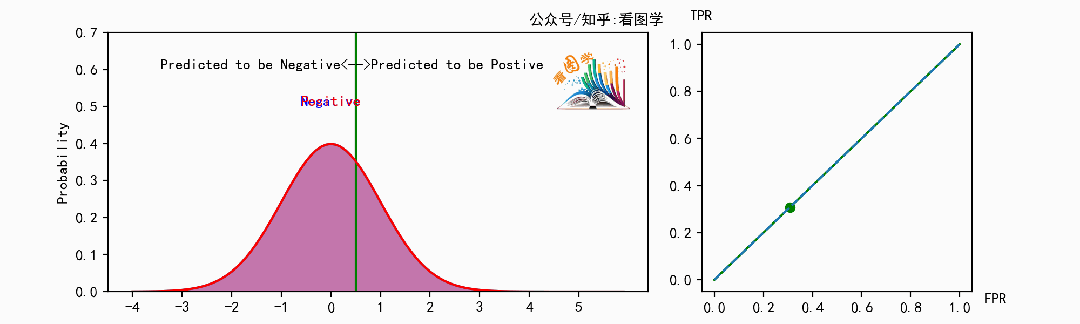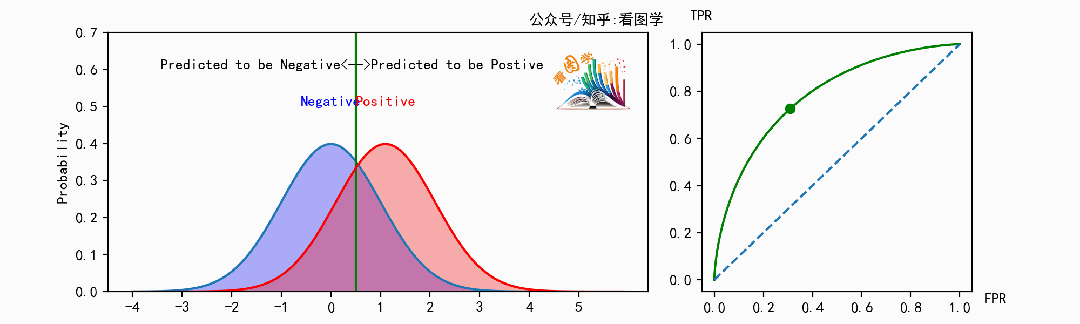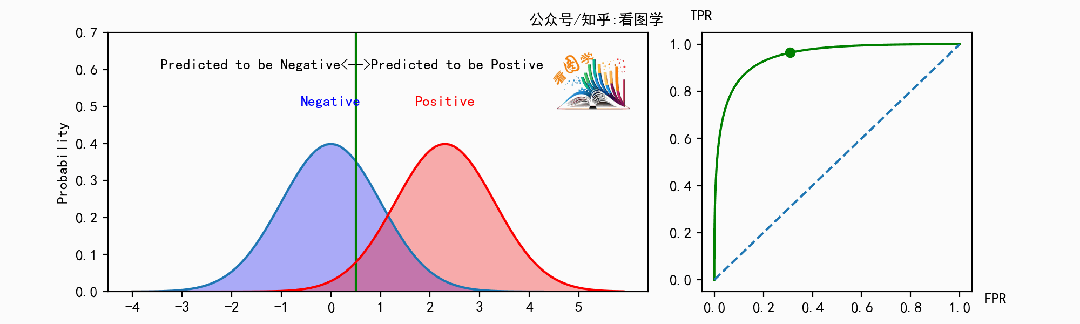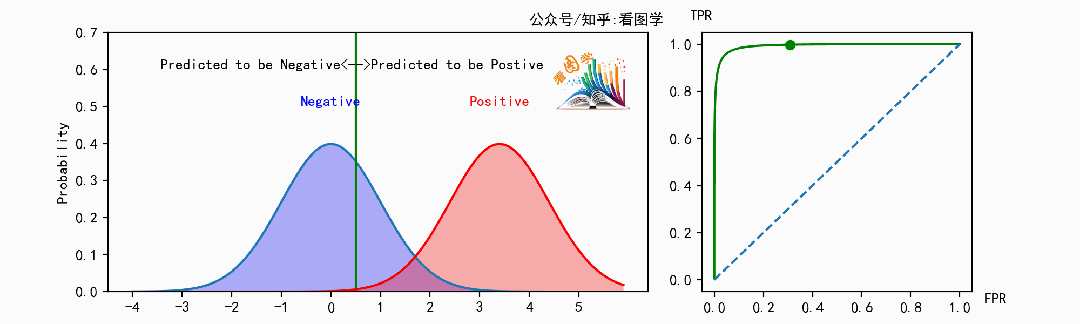
可以看到,当分类器能力越来越好时,曲线会往左上角(最优点)靠拢。此时可以用曲线下的面积来表示分类器的能力, 叫做 AUC, AUC是ROC曲线下的面积( Area Under the ROC Curve)。
虽然大家都知道 AUC 越大越好,但是 AUC 的值到底代表了什么呢?这个放在下期更新。
“ROC-AUC 曲线是什么?怎么计算?” 小米一面,问的贼细
17.Qwen 从头开始训练的初始 loss 大概是多少?
我们在训练模型的时候,会观测很多指标。诸多指标中, loss 肯定是最重要的指标之一。所以训练模型的第一件事,往往都是看 loss 算的对不对。
这个经验很重要,尤其是现在模型越来越大,训练时经常要做一些 Tensor Parallelism 或者 Pipeline Parallelism。那么有没有正常训练?这个时候看一下 loss 是否符合预期,以防止白白浪费算力。
那么从零开始训练的初始的 loss 大概是多少呢?
这个完全可以推算一下。
这里有一个假设,就是参数随机的情况下,假设预测下一个 token 的概率符合均匀分布,也就是所有 token 的概率是相同的。
如果词表的大小是 |V|, 那么第 i 个词的概率都是$\frac1{|V|}$
由于采用交叉熵损失,label 又是 onehot 的, 那么下一个词的 loss 为:
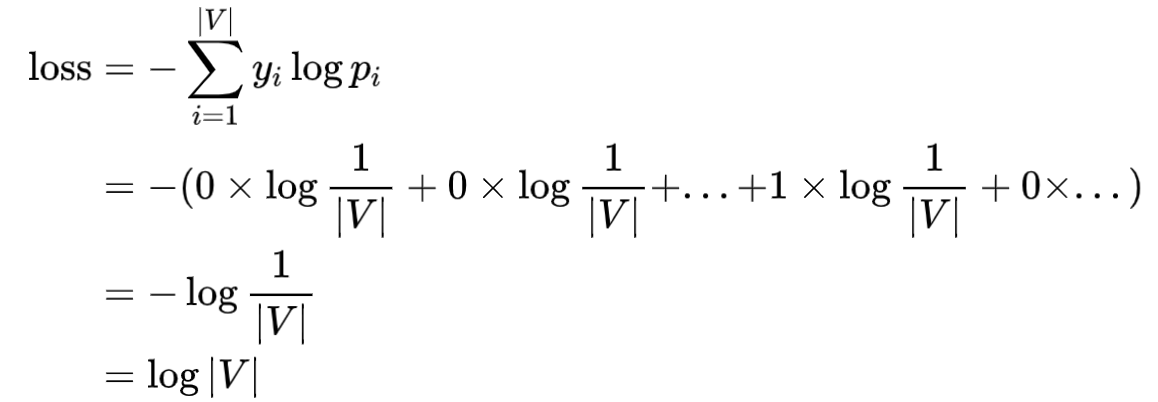
Qwen 的词表大小为 152064, 所以其初始 loss 大概为 $\log152064=11.932$
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
