公众号“看图学”试题合集(2)
Last updated on February 11, 2025 pm
1. 大模型的参数量为什么设计成 7B,13B,33B,65B 等如此怪异的数字?
1.1 从推理出发
很多答案都是从推理出发,认为之所以这么设计,是为了适配常见的显卡。
比如,采用半精度的话
- 7B 的模型参数占14G, 可以放到16G 的 T4 上
- 13B 的模型参数占26G, 可以放到 32G 的 V100 上
- 33B 的模型参数占66G, 可以放到 80G 的 A100 上
- 65B 的模型参数占130G, 可以放到两张 80G 的 A100 上
剩余的显存可以用来放 KV Cache, 还有其他的一些功能性显存占用,比如 beam search 等。
这么回答也算合理,****但是只能算是回答了一个方面,而且不是最重要的方面。
1.2 沿用GPT3的参数标准

GPT 3 当时选定了 6.7B, 13B, 和 175 B。后面复现的人得做对比实验吧,那自然要对标 GPT 3,不然一个 6.7 B,一个 10 B,那对比起来也没什么意义。
所以这些参数的设定可以说是从 GPT 3 传下来的,因为大家都想和 GPT 3 PK 一下。所以那个时候很多模型都是 7B 和 13 B 左右,但是略有差异,也许是 6B,也许是 14B。
字节校招一面:“大模型的参数量为什么设计成 7B,13B,33B,65B 等如此怪异的数字?”
2. 为什么 Qwen 设计成 72B?
3. torch.no_grad() 和 torch.inference_mode() 的区别?
torch.no_grad() 和 torch.inference_mode() 都在推理的时候禁用了梯度计算。
虽然从功能上两者类似,但是这两者的实现有很大的不同。
torch.no_grad() 属于是在 pytorch 原有的机制上禁用了梯度的计算,底层还是有梯度计算的框架(autograd),属于可以算,但是逻辑上不进行计算。
但是 torch.inference_mode() 的是完全另起炉灶,完全脱离了 autograd 系统,而且把 View Tracking(视图追踪)和 Version Counter Bumps(版本计数器更新)同样砍掉了。从底层上就完全放弃了梯度计算的逻辑。
举一个不太恰当的例子,为了追求更快的推理速度,torch.no_grad() 的选择是加入少林寺,远离俗世的一切联系,专心推理,但是还是可以还俗的。而 torch.inference_mode() 则是练了辟邪剑谱,从根本上断绝了俗世的干扰。
那你说谁的推理速度快,当然是练了辟邪剑谱的更快。
代码演示
1 | |
上述代码中,如果采用 torch.no_grad(), 则可以正常运行。但是如果采用 torch.inference_mode(), 则在三个检查点都会 fail。
第一个检查点是 Version Counter Bumps。因为有时候 tensor 会在原地修改以避免内存的拷贝,加快运行速度。所以每个 tensor 都有一个 version。
第二个检查点是 View Tracking, 这个主要是 tensor 当作一些 视图(view) 上的变化,比如view()、reshape()、transpose() 等,这些虽然呈现为不同的形状,但是底层的内存是共享的。这就要有一个机制来追踪这些视图。
第三个检查点则是 Autograd。因为 torch.inference_mode() 压根就没有 Autograd 的梯度计算机制,所以当试图修改梯度计算状态的时候也会失败。
4. model.eval() 会像 torch.no_grad() 那样停止中间激活的保存么?
不会。model.eval() 和梯度的计算是正交的,各算个的,可以认为完全没有任何关系。
上周的一篇:《学妹问:“model.train() 和 model.eval() 什么作用?” 我给她分享了个bug》发布后,有朋友私信说 model.eval() 是否和 torch.no_grad() 类似,停止中间激活的保存?因为推理也用不到反向传播。
然而事实是 model.eval() 除了上篇文章中说的适配训练和预测的不一致性以外,再也没有做更多事情了。
像是停止中间激活的计算,禁用反向传播,节省内存等等,都是大家根据 eval 这个名字臆想出来功能。****就跟川普要当总统了,然后股民看到“川大智胜”疯狂买入导致涨停是一样的。
至于 torch.no_grad() 则是将该上下文中的所有变量都不在参与梯度的计算,所以中间激活,梯度都都不需要保存了,自然可以省一些显存。
但是一定要注意,torch.no_grad() 虽然不计算中间激活和梯度,但是 autograd 的计算图还是在的。
当退出 torch.no_grad() 后,后续的代码依然运行在 autograd 的计算图上。如下面的小例子。
1 | |
在退出计算图后,执行 y.requires_grad = True 是可以的,因为整个的 Autograd 体系还在。
当设置 y 处在 torch.no_grad() 的上下文后,y 之前的梯度都没有了,即使 x 设置了 requires_grad 为 True。
但是 y 之后的 z 则可以正常的求导。整个求导过程在 y 就被熔断了。
5. model.train() 和 model.eval() 什么作用?
model.train() 会让模型进入 train mode,而 model.eval() 会让模型进入 eval mode。
为什么要有这两种模式呢?是因为模型中的有些模块在训练和预测不一致导致的。典型的模块就是 Batch Norm 和 Dropout。
Batch Norm
对于 Batch Norm 来说,训练的时候其实并不关心整体样本的均值和方差,我只需要在我这个 batch 内稳定训练就可以了。
但是预测的时候,我们也必须得找一个均值和方差。那最好的选择就是通过整体的样本来进行估计了。
但是这里面又有一些细节,比如原始论文中训练时方差用的是有偏估计,但是推理的时候用的是无偏估计。这个问题在几年前一直是个讨论的热点。甚至 github 上有个 2017年的 issue,7年了,到现在还没 close。https://github.com/pytorch/pytorch/issues/1410
Dropout
Dropout 的训练和预测也不一致。
训练的时候会随机 drop 一些神经元,但是预测的时候则是使用全部的神经元然后进行缩放。
正是由于这种训练和预测的不一致性,就导致我们必须要告诉模型,什么时候是训练的状态,什么时候是预测的状态。
我之前还写过一个目前还有印象的bug,就是 model.train() 写了在 for 循环迭代外面,结果 for 循环里面调用了一个评估函数,在评估函数里面会执行 model.eval(),结果就导致 model 基本全程处于 eval 状态。
适配 train 和 eval
有时候我们自己写模型,可能也会存在训练和预测不一致的情况,怎么适配 model.train() 和 model.eval() 的接口?
只需要改变 torch.nn.Module 的 is_training 状态即可,比如下面的代码:
1 | |
就是这么简单。
6. 如何防止 Checkpoint 注入代码攻击?
答案
使用 safetensors 存储和加载。攻击原理和防范方法还有代码演示见后面。
但是这个方案也只能是防君子不防小人。只要一个人想干坏事,有太多的方法来实现了。但是对于公司来说,还是提高一些做坏事的门槛比较好。
攻击原理和防范
稍微说一下利用 checkpoint 进行攻击的原理。
其实也并不是什么特别高明的技术,核心就是 pytorch 的开发人员偷懒,在保存和加载模型的时候,采用了 pickle 格式,而 pickle 格式本身就是不安全的。
更具体一点来说,pickle 设计的初衷是为了方便的序列化和反序列化数据。而为了方便用户自定义自己的序列化方式,开放了一个 __reduce__ 的接口,而这个 __reduce__ 接口则可以让用户为所欲为,如果有足够的权限,用户甚至可以在里面执行 rm -rf /。
所以后来 huggingface 推出了 safetensors 的格式。这个格式就是一份数据,不能执行代码。而且优化了加载速度,还可以在不加载权重的情况下就获取数据的 meta 信息,比如模型的网络结构等。所以以后大家尽量用 safetensors 就好了。
下面的代码,加载模型后进行代码注入(这里以让系统 echo hello world 为例,如果load模型后系统打印了Hello World,则表示攻击cheng g),然后使用使用 pytorch 来存储和加载模型,可以发现用torch.load 被注入代码的模型后,打印了 Hello world。而采用 safetensors 则没有任何问题。
为了防止攻击代码的恶意扩散,下面的代码中具体的注入方式被隐藏。想学习完整代码可以看文末的付费专栏,日后要是惹出祸事,不要说是我教的。
1 | |
7. 分布式训练常用的通信后端都有什么?应该怎么选?
目前最流行的深度学习框架当属 Pytorch ,Pytorch 支持3个通信框架:MPI,Gloo,NCCL。
但是也有很多自研的框架,比如阿里的 ACCL, 微软的MSCCL, Intel 的 oneCCL, AMD 的 RCCL, 华为的 HCCL 等。
通过名字大概可以看出,这些通信框架大致分为两类, MPI 和 xCCL。
MPI 的全称是 Message Passing Interface。而 CCL 的全称是 Communication Collectives Library。然后前面还会加一个代号,来区分是哪家公司的。比如 NCCL 就是 Nvidia Communication Collectives Library, 阿里的就是 Alibaba Communication Collectives Library,也有不是公司名的,比如 Intel 和 AMD 分别用了 one 和 ROCm。
下面分别简单介绍一下这些框架。
MPI
经典的分布式通信框架。当年在百度的时候,经常用 MPI 版的逻辑回归。那个时候刚出校门,没见过世面,感觉分布式训练贼牛逼。
在 NCCL 出现之前,MPI 在 CPU 和 GPU 分布式框架中都占据主导地位。不过自从 NCCL 出现后, MPI 目前只用在 CPU 的通信场景中了。
Gloo
Gloo 是 Facebook 的开源框架。对 CPU 和 GPU 的通信都做了一些优化。早期的时候,优化的算法不太多,现在也加了很多优化算法,具体见:
https://github.com/facebookincubator/gloo/blob/main/docs/algorithms.md
但是在 GPU 上,效果依然没有 NCCL 好,所以目前只要用 Nvidia 的 GPU,基本上都会把通信后端设置为 NCCL。
NCCL
NCCL 是英伟达开发的。当时的起因是 MPI 虽然也对 GPU 做了优化,但是并没有完全发挥出性能,所以英伟达亲自下场,在传输和计算的 overlap 上做了很多优化工作。
一经发布,就成了业界扛把子。只要用 Nvidia 的卡,用 NCCL 就行。
NCCL 会自动根据网络拓扑和通信协议来自动选择算法,比如 Ring based, Tree based 或者 CollNet,选择一个最快的来运行。
体感上来看,NCCL 在最开始通信的时候由于有一些前置步骤,所以第一次通信的时候很慢,但是只要开始通信之后,就非常快了。所以测速度的时候千万不要把第一次通信的时间当作结果。
英伟达也并没有想着要取代 MPI,而是采用了共存共荣的策略,只在 GPU 上优化。
MSCCL
MSCCL 是微软开发的,可以认为 NCCL 的一个扩展。关键是可以兼容 NCCL 的 API,pytorch 只需要将 backend 做一下替换即可。
MSCCL 提供了更灵活和可定制的集体通信算法,引入了一个 chunk-oriented dataflow language, 叫 DSL。同时还有个编译器,用来编译和优化数据如何在 GPU 之间进行流动。这个工作还是比较硬核的,光编译原理估计大部分人就看不懂。
根据他们的测试报告,MSCCL 在推理上可以加速1.22x–1.29x, MoE 的训练可以加速 1.10x–1.89x 。
ACCL
阿里针对阿里云的环境进行的优化。其官网上是这么写的:
- 修复了对应NCCL社区开源版本的BUG;
- 对集合通信不同算子和不同消息区间进行了调优,使其相比开源NCCL拥有更好的性能;
- 支持训练过程中集合通信统计分析,可用于诊断训练过程中设备故障导致的计算/通信Slow(慢)和Hang(挂起)等问题,配合阿里云PAI的AIMaster:弹性自动容错引擎和C4D:模型训练任务问题诊断工具,可以快速的进行任务的异常检测和自动容错;
- 支持多路径传输和负载均衡功能,在训练集群中降低甚至消除哈希不均导致的拥塞问题,提升整体训练性能;
HCCL
华为开发的,基于昇腾硬件的高性能集合通信库。现在很多公司已经在采购昇腾的卡了。
现在老美一直打压我们,那天要是 Nvidia 的卡不让用了,只能用这个了。
oneCCL/RCCL
oneCCL 是 Intel 开发的,RCCL 是 AMD 开发的。
看这两家的背景就知道,这两个库在更底层上进行优化,所以对InfiniBand、以太网有很好的支持。
到底用什么
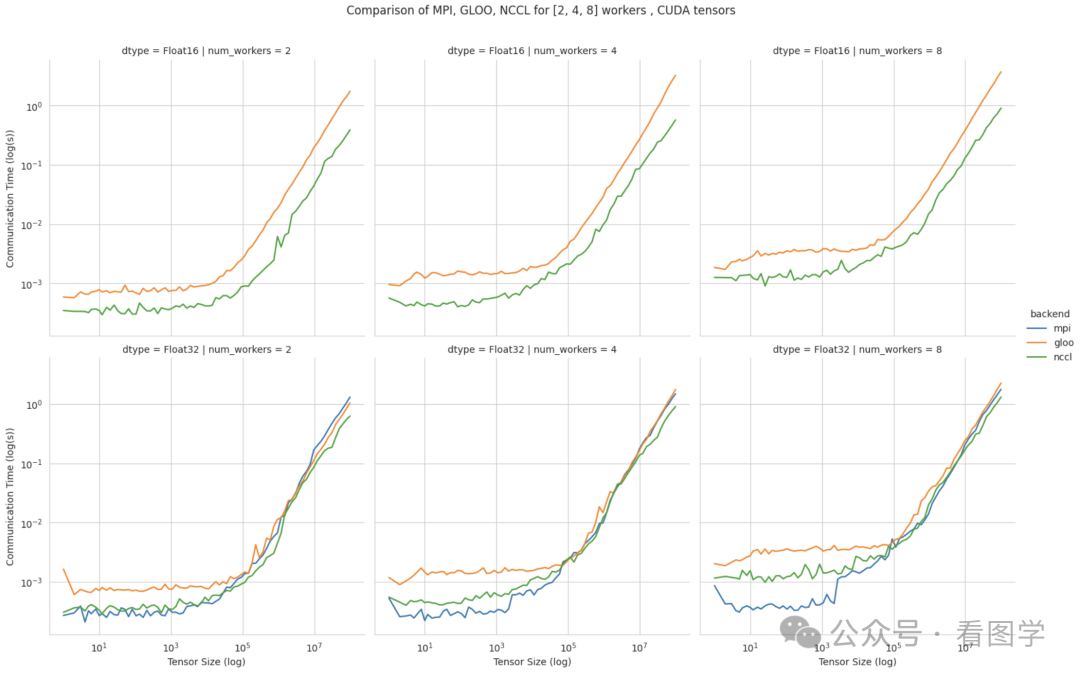
之前有人对 MPI, NCCL 和 Gloo 做了测评,结论是:
- 当 tensor 比较小时,MPI 的性能更好,而且集群数量越大,MPI 效果越好。
- 当 tensor 比较大时,NCCL 性能最好,而且跟集群没有关系。
最终的结论就是:
- 用什么型号的 GPU,就用对应的 CCL。比如 N 卡就用 NCCL,阿里的就用 ACCL,昇腾的就用 HCCL。
- 如果是 CPU,最简单的就用 Gloo。爱折腾就用 oneCCL 或者 RCCL。
当然 pytorch 官方也给出了使用建议,请看:https://pytorch.org/docs/stable/distributed.html#which-backend-to-use
8. Beam Search 的缺点?
Beam Search 大大提升了推理的速度,但是其自身也有很多缺点。下面分别说明
缺点1: Beam Search 本身并不能保证找到最优解。
当 beam size 为1时, Beam Search 就退化为 Greedy Search,当 beam size 趋向于无穷时,则变成暴力穷举,这个时候才能保证最优解。
当 beam size 变大时,找到最优解的概率会提升,但是收益是递减的。
缺点2: Beam Search 趋近完美且中庸,但没有惊喜
之前有人问余华 AI 是否对作家构成威胁。余华老师估计不太懂 AI 的底层原理,但是他却给出了一个非常接近本质的结论。
余华认为:生活是不按常理出牌的,AI 写作可以写出中庸的小说,但写不出个性的小说。人脑总要犯错误,用人脑写作的“伟大文学作品都有败笔”,但这也是人脑最可贵之处。
需要注意:中庸并不是一个贬义词,讲究的是不偏不倚,折中调和。
通过对人类文本和 Beam search 生成的文本的困惑度进行对比,也验证了这一点:
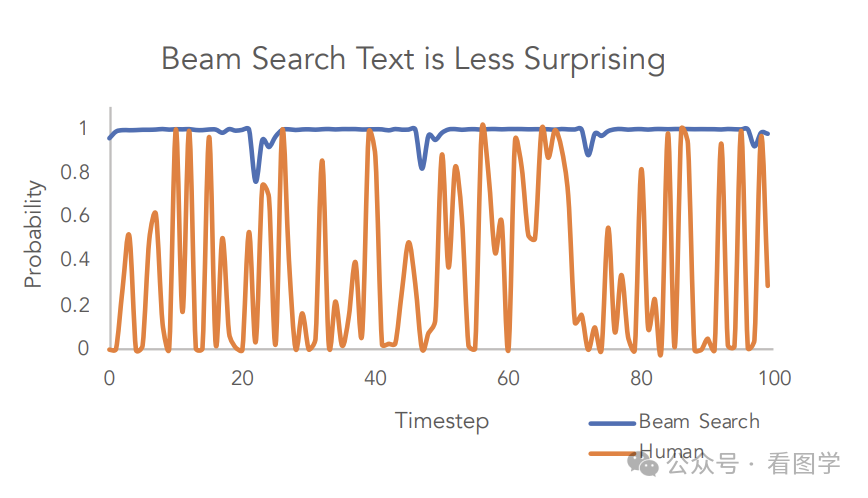
所以 AI 生成的文本往往比较枯燥,没有带来惊喜。甚至在某些情况下,会陷入 positive feedback loop, 倾向于重复的输出一些高概率的词。
缺点3: Beam Search 对长序列不友好
由于 Beam Search 的概率是累乘的,由于概率又小于1,所以随着长度的增加,句子的概率会越来小。
这也就造成一个长度为 5 的句子的概率,天然就大于长度为100 的概率。所以 Beam Search 更喜欢短句子。
通常需要对 Beam Search 进行 Length Normalization。
缺点4: Beam Search 会耗费额外的资源
尤其是当 beam size 很大和序列长度很大的时候,beam search 会耗费不少的内存。比如 KV Cache 的存储。
当然可以通过 Trie 树等来进一步优化。
9. Beam Search 最坏时间复杂度是多少?
答案
Beam Search 相信大家都知道怎么回事,这里不再赘述。本文探究一下 Beamsearch 的时间复杂度。
假设大模型的词表个数为|V|,我们要预测 个 token,beam search 的 beam size 为k, 那么beam search 的时间复杂度是多少呢?
我们先看下 beam search 的搜索路径,如下图所示(beam size = 2):
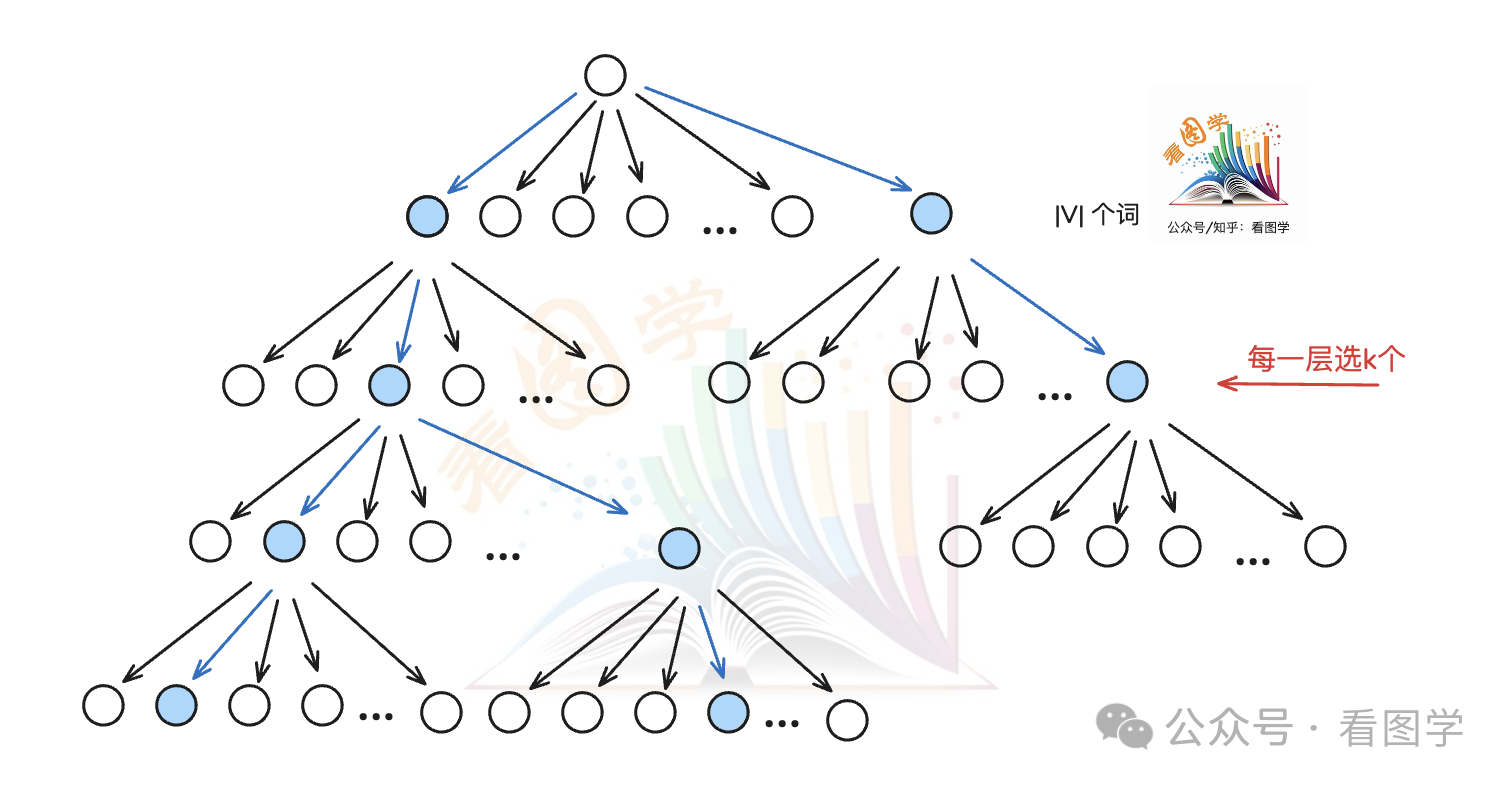 第一个 token 时从|V|中选择 k个概率最大的 token ,剩下的都是从 k|V|个候选 token 选择k个概率最大的。
第一个 token 时从|V|中选择 k个概率最大的 token ,剩下的都是从 k|V|个候选 token 选择k个概率最大的。
从N个数字中选择k个最大的数,经典的 topk 问题。
top k 问题也经常作为算法面试题出现,但是能完全答对的真不多。这里给出 4 个选项:
$$
\begin{aligned}&\bullet\text{ А.}O(N\log N)\&\bullet\text{ В.}O(N\log k)\&\bullet\text{ С.}O(N)\&\bullet\text{ D.}O(N^2)\end{aligned}
$$
可以先选择一下再给答案。评论区可以发一下自己的答案:)
下面分别说明
- O(NlogN)
这个时间复杂度肯定可以完全解决,只需要将 数组排序,然后选择最大的 k 个即可,排序的时间复杂度为 O(NlogN)。但是并不是最优的。少数排序算法可以达到O(N),但是ROI不一定实用。
- O(Nlogk)
可以维护一个大小为 k 的小顶堆,然后遍历 N 个数,每次更新小顶堆的时间复杂度为 logk,整体为Nlogk. 最后堆内的元素就是答案。
- O(N)
参考 quicksort,每次选一个 pivot 进行重新排列。但是我每次并不 sort,而是 select,把问题变成 quick select.
只要我知道了第 k 大的数字,再 O(N) 的遍历一遍,就得到了 TopK 的数字了。
N个数一次 parition 的时间复杂度为 O(N), 下一次处理的数量期望是当前数量的一半。所以整体期望的时间复杂度为 $O(N)+O(N/2)+O(N/4)+\ldots=O(2N)=O(N)$
但是注意,这只是期望是 O(N).
如果下一次处理的数量并不是一半,而是只少了一个,那么最坏的时间复杂度则变成 .
其实回答到这里,基本就可以了,下面的是加分项。
但是实际上,quick select 可以进一步转化为使用 Median of medians 算法来求解 TopK。
而 Median of medians 算法是一个真正的线性算法,可以最坏 O(N)的时间复杂度来找到第 k 大的元素。
虽然理论上, Median of medians 的最坏时间复杂度是O(N),但是它的渐近常数有点大,实际使用中其实和 quick select 差异并没有那么大。它的意义就是保证了 TopK 的最坏时间复杂度为线性。
Median of medians 算法也很简单,这里就不写了,感兴趣的可以看下面的付费资料。
Beam Search 的时间复杂度
回到 Beam Search 的问题上,由于每次是从k|V|个元素中选择 k 个,这种选择进行了 n 次,所以 Beam Search 的时间复杂度为O(nk|V|)
当k=1的时候, 退化为 greed search。
当$k=\infty $ 的时候,不能直接带入到式子里面,因为k 虽然可以无限,但是刚开始的搜索步骤还是有限制的。这时候相当于 全局搜索,时间复杂度为 $|V|^n$
10. 为什么 sigmoid 采用的是 e 的负 x 次方,而不是别的数的负 x 次方?

不同 k 值的函数图像如下图所示:
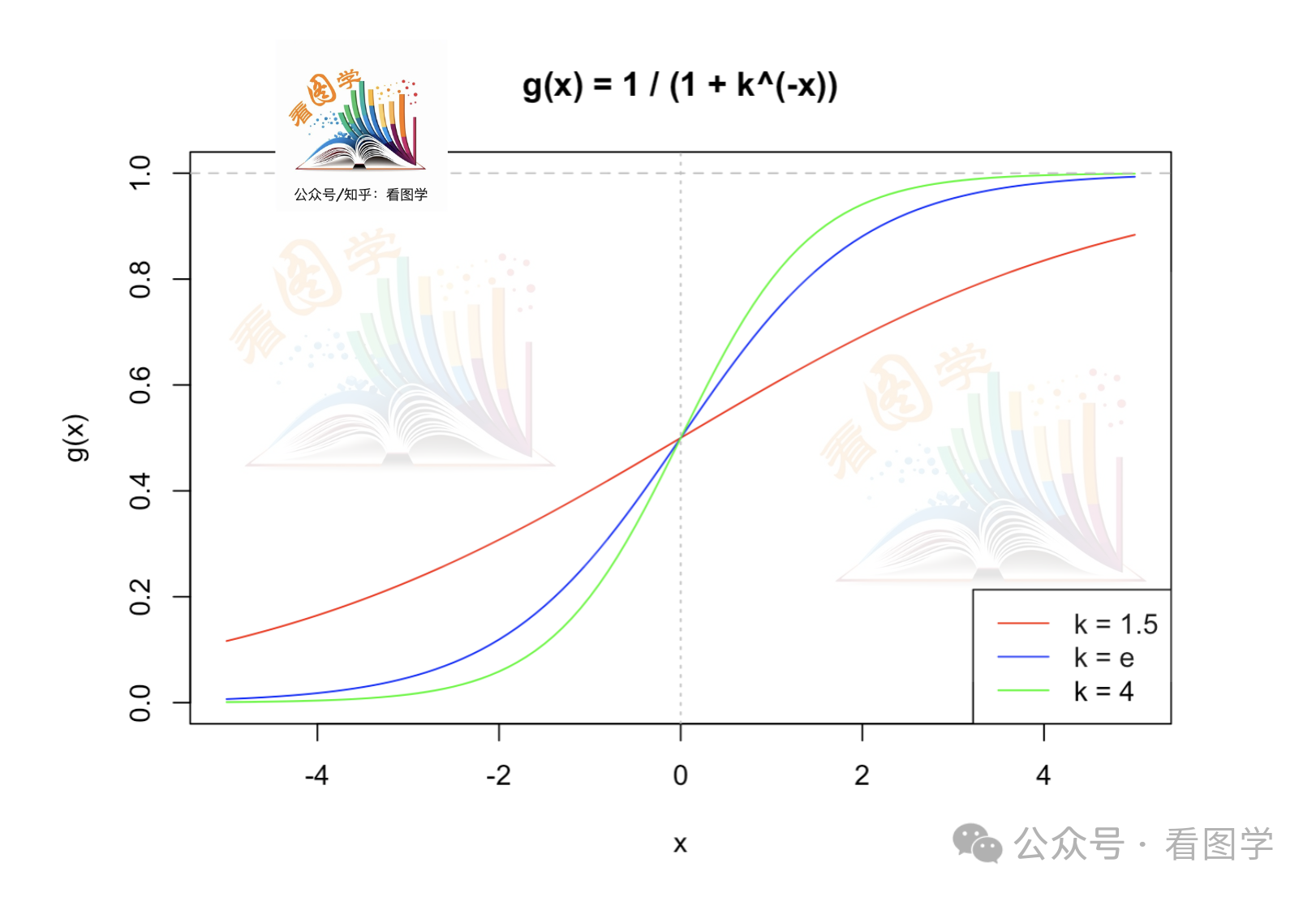
看到这里我大概意识到不同的 k 只是对 sigmoid 做了不同的拉伸,其实都属于 S 形函数。
这类函数不仅函数相似,其导数也高度相似。然后我决定推导一下 g(x) 的导数。如下:
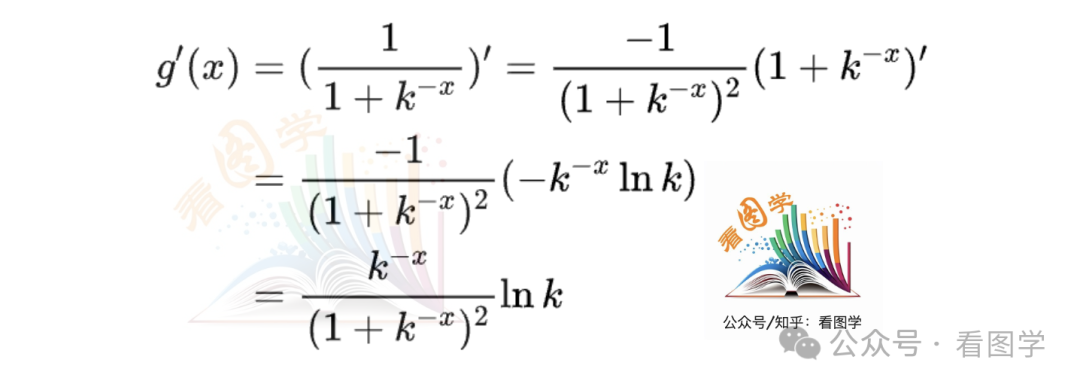
联想到 sigmoid 的导数为
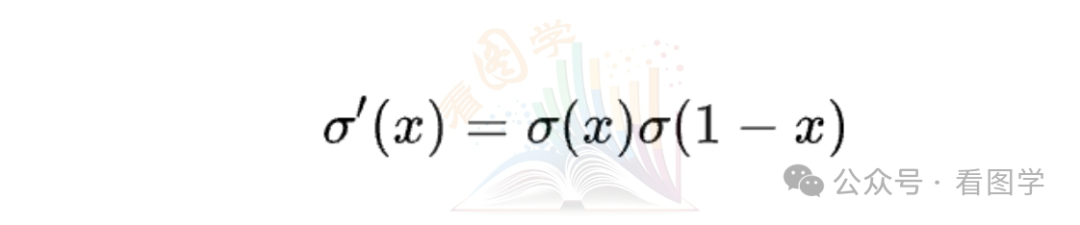
好像知道答案了。g(x) 的导数可以继续化简,为:

所以说导数这里有个 ln k 的常数。
一是为了计算的简便,当 k = e 时,这一项就没有了。
二是联想到 ResNet 的导数,里面如果含有一个常数项,累计效应会造成训练的不稳定,具体的推导可以看:字节大模型一面:“为什么现在深度学习都用 ResNet?”
我觉得这应该是 k 取 e 的原因吧。
晚上吃完饭又想了想,这个 ln k 的常数是怎么出来的呢?突然我一拍大腿,发现其实上面的证明有点绕远路了。
因为$k=e^{\ln k}$ , 然后
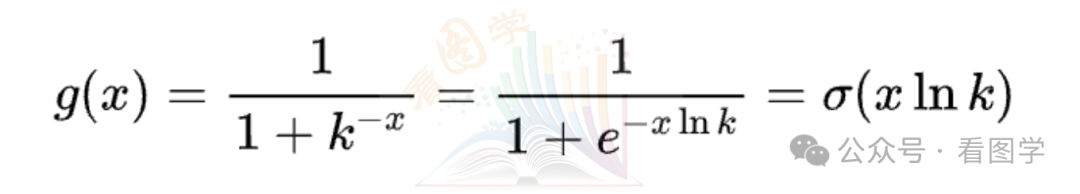
所以 g(x) 依然是 sigmoid.
根据链式法则,
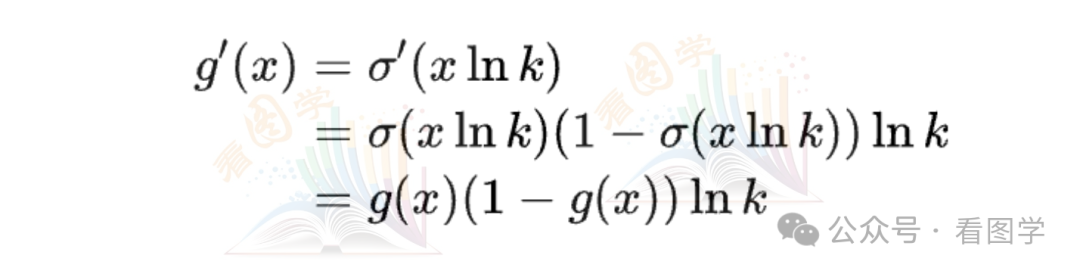
这就是 ln k 常数的由来。
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
