公众号“看图学”试题合集(3)
Last updated on February 13, 2025 pm
1. tanh 和 sigmoid 什么关系?为什么 tanh 作为激活函数比 sigmoid 要好?
sigmoid 的性质导致其导数全为正数,详细看:我用Sigmoid 作为激活函数,导师建议延毕,导致这样的其中一个原因(并不是全部的原因)是:sigmoid 的值的范围在 0-1 之间。
如果将 sigmoid 函数变成 zero centered, 那么其值就有正有负, sigmoid 收敛慢,不稳定的原因就解决了。
那么 sigmoid 如何 变成 zero centered 呢?
sigmoid 的范围在[0, 1] 之间, 其实只需要减去 0.5 就可以了,这样就变成了 [-0.5, 0.5] 之间。
我们定义这么一个的函数:
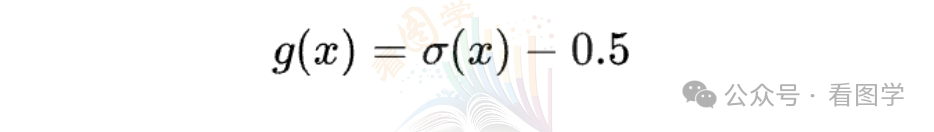
我们把这个式子推导一下,看看能得到什么

结果另一个常用的激活函数就出现了。
结合上面公式,tanh 也可以写作
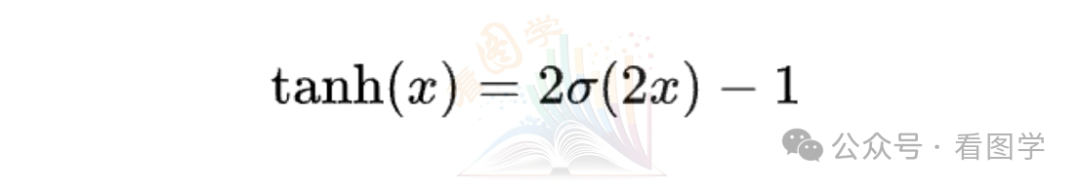
所以 tanh 作为激活函数,本质上就是对 sigmoid 做了个 zero centered 操作, 先把 sigmoid 在x轴挤了一下,然后在 y 轴上拉伸,最后减去中心点,相当于平移成一个 zero centered 的函数。
其实我感觉不做这些缩放的变换,直接用 g(x) = σ(x) -0.5 作为激活函数也是完全可以的。
这样解决了梯度全为正(或者全为负)的问题。
但是毕竟跟 sigmoid 是同源的,依然没有解决梯度消失的问题。
下面是 tanh 的导数 和 sigmoid 导数的对比:
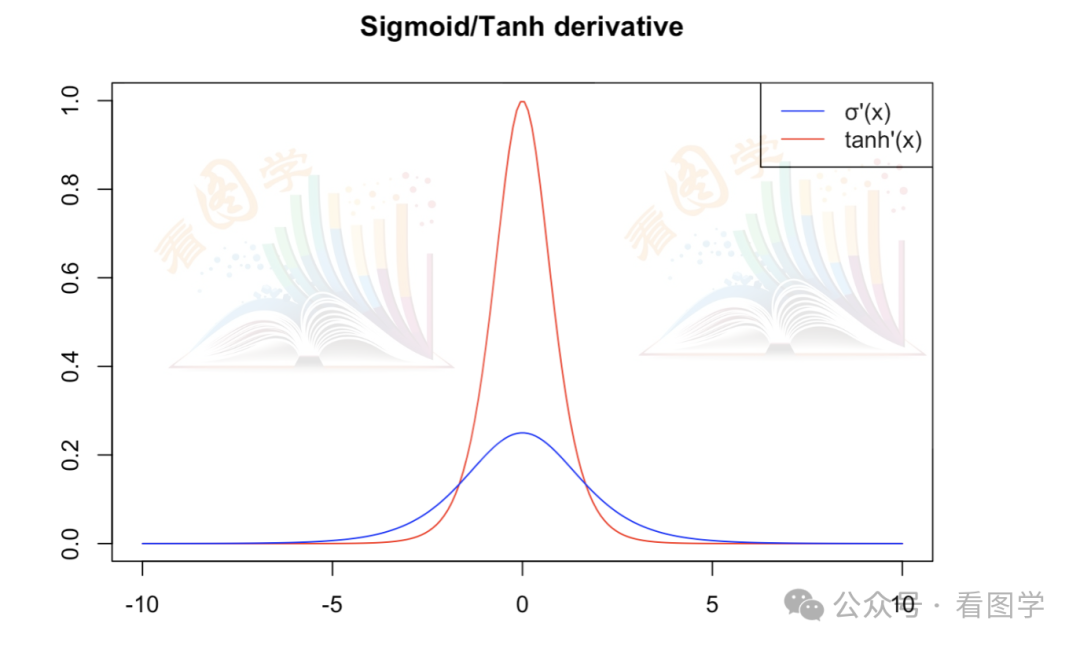
可以看出,tanh 的饱和区大概在 [-3,3] 之间。
但是即使这样,tanh 在实际的使用效果上,已经比 sigmoid 要好很多了。
2. 基于 Llama 的模型都有哪些?有什么细微的差异?
Llama 生态
现在的模型架构基本都是 Llama 了。即使本来也有一些自己独创的结构,但是随着 Llama 生态环境的日趋统一,也都被迫向 Llama 低头了,不然没人适配你的特殊架构,自然就不带你玩了。比如 GLM 之前属于 Prefix LM,但是现在也变成 Llama 类似了。
虽然大家都长的很像,但是细微之处还是有些不太一样。今天就聊聊跟 Llama 很像的模型之间的细微差异。
Llama 目前有3代,先看一下 Llama 自己的变化,然后再以 Llama 为基准看一下其他模型与 Llama 的不同。
Llama 1 2 3
Llama 1
Llama 1 的架构是基于 GPT 来的,做了如下的升级:
- 采用了 Pre-RMSNorm
- 把 Gelu 改成了 SwiGLU
- 位置编码改成了 RoPE
需要注意的是,这些内容都不是 Meta 首创的,但是 Meta 的 Llama 团队将他们组合到了一起并且取得了开源的 SOTA 效果。至于闭源的,那肯定早都用了。
其结构如下所示(Llama 7B):
1 | |
Llama 2
Llama2 和 Llama1 结构基本相同,但是在更大的模型上(34B和70B) 采用了 grouped-query attention,主要是为了加速。
还有就是将上下文从 2048 扩展到了 4096.
Llama 3
Llama3 做了如下改变
- GQA 变成标配。
- 上下文 从 4096 扩展到了 8192
- 词表大小从 32k 变成了 128k。前两代都是基于 SentencePiece 的,Llama 3 直接采用了 Openai 的 tiktoken。因为 tiktoken 用 rust 进行了底层的深度优化,效率比其他家要好很多。
Baichuan 系列
Baichuan 1
Baichuan 1 可以说是完全复用了 Llama 1 的架构。把权重的名字改一改可以完全用 baichuan 的代码来加载 llama 的权重。具体怎么修改的代码放在付费内容了,感兴趣可以看看。
有如下的差异:
- llama 的 qkv 三个权重矩阵,在 baichuan 里变成了一个矩阵,相当于 qkv concat 起来了。
- 扩充了 llama 的词表,加入了中文,词表大小为 64k,llama 1 为 32k。
- 上下文为 4096, llama 1 为 2048.
Baichuan 2
Baichuan 2 的架构在 Llama 2 的基础上做了一些创新。
- 在 lm_head 模块加了一个 norm,论文中说是可以提升效果
- 在 13B 的模型上采用了 Alibi 位置编码。
- 词表从 64k 扩充到了 125,696
Baichuan 3 & 4
没有开源。
Yi
yi 的架构和 llama2 一样。需要注意的是 llama2 只在更大的模型上使用了 GQA, 但是 Yi 在所有系列都用了。
在经历过一些开源协议的质疑之后,现在 yi 的模型可以用 LlamaForCausalLM 加载了。
Qwen
Qwen 1
Qwen 1 和 Llama 1 的区别如下:
- qkv 矩阵和 baichuan 类似,变成了一个 concat 后的大矩阵。
- 这个 qkv 的矩阵有 bias,这一点和大多数模型都不一样。这是因为苏剑林的一篇文章,认为加入 bias 可以提高模型的外推能力:https://spaces.ac.cn/archives/9577
- 词表大小为:151936
- 训练的长度是2048, 但是通过一些外推手段来扩展长度。
Qwen 1.5
其实 Qwen 1.5 开始,比起 Llama 就多了很多自己的东西,只不过 Qwen 1 仍然和 Llama 很相似,所以这里也一并写一下吧。
1.5 的版本更像是在 1 的基础上做了很多扩展,重点如下:
- 扩展长度到 32K
- sliding window attention 和 full attention 的混合
- 32B 的模型尝试了使用 GQA
- tokenizer 针对代码做了一些优化。
Qwen 2
Qwen 2 包含了 1.5 的所有改变。和 llama 2 的区别:
- qkv 矩阵有 bias
- 全尺寸使用了 GQA
- 上下文扩展为 32K
- 采用了 Dual Chunk Attention with YARN
- 还有一点就是在同等尺寸上,Qwen 2 相对于 1.5 和 1,将 MLP 模块的 hidden size 变大了,其他模块的 hidden size 变小了。以提高模型的表达的记忆能力。
- 词表又扩充了一点点。
ChatGLM
GLM 最开始的时候采用的是 Prefix LM,但是后来也都改成 Decoder Only LM 了。
所以虽然 GLM 要早于 Llama,但是最后还是和 Llama 变得很像。上面提到的其实最像 Qwen 1.
所以也说一下与 Llama 的区别:
- qkv 矩阵和 baichuan 类似,变成了一个 concat 后的大矩阵。
- 这个 qkv 的矩阵有 bias。
MiniCPM
目前已经转战 size 略小一点的模型,也取得了很不错的效果。
我粗看其架构应该和 llama 3 差不多,区别:
- 采用了 Weight Tying
- 整体框架采用了 deep and thin 的结构。
有个细节是,我看论文里写的词表大小为:122,753, 似乎有点非主流。因为一般都需要设置成 8 或者64 的倍数。具体可以看:NLP 面试八股:“Transformers / LLM 的词表应该选多大?” 学姐这么告诉我答案
Gemma
我要说 Gemma 是基于 Llama 的,Google 肯定是不承认的。
Google 有不承认的底气,毕竟 Transformers 是人家搞出来的, GLU 也是人家的,MQA 和 GQA 也是人家搞出来的。
最终发现 Llama 中除了 Pre-RMSNorm 和 RoPE,其他都是 Google 的成果。只能说 Google 真的是 “斗宗强者,恐怖如斯”。
但是最后的架构和 Llama 其实还是很像。区别如下:
Gemma 1
- MLP 的激活采用了 GeGLU 而不是 SwiGLU
- 采用了 MHA。但是 2 代还是换成了 GQA
- 使用了 Weight Tying
Gemma 2
- MLP 的激活采用了 GeGLU 而不是 SwiGLU
- 融合了 Local and Global Attention
- 使用了 Weight Tying
其他
至于 Mistral 和 DeepseekV2 和 Llama 还是有些不太一样,所以这次就先不介绍了。
3. 大模型一个 token 能代表几个单词和汉字?
答案
每个模型的 Tokenizer 都不太一样,所以这个问题不能给出很精确的答案,更多的是考察一些大模型的使用经验。
**文末有一些目前 Tokenizer 的看法,感兴趣的可以讨论。
**
也可以换着法子问,比如 一段一万字的 prompt,输入到最大长度为 8192 的模型,是否能正确的输出?
但是每个模型的 Tokenization 都是在自己的语料上训练出来的,怎么知道具体某一个 Tokenizer 每个 token 平均代表几个汉字呢?
有的模型的技术报告会在 Tokenization 那一章提供一个“压缩率” 的指标,比如 qwen 和 baichuan 的,但是有些技术报告并不会提。
虽然说不同的 tokenizer 在不同的训练语料上训练的不一样,但是大家采用的方法其实无非就那么几种,感兴趣的可以看:小米面试官:“Tokenization 是什么”。封面看着眼熟
其实只要训练语料里主要的语言一样,在大量数据的堆积下,最终的的结果差异并不大。下面会给出以 英文为主的模型和中英文为主的模型的一些结果对比。
为了测试,我选择了两本小说,《孔乙己》 和 《哈利波特》第一章,分别测试不同 tokenizer 对这两篇小说的中文版和英文版的效果。
结果如下图所示:

虽然这只能算是个抽样,但是也能看出一些问题。
每个模型在英文上的效果基本差不太多。一个 token 大概占 0.75~0.8 个单词。这与 OpenAI 官网上写的差不多:“A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).”
国内的模型在中文语料上特训之后,中文编码的效率显著高于英文的 ChatGPT 和 Llama。一个 token 大概占1.5 个汉字。
目前的 Tokenizer 的编码效率够么?
周一曾经写了一一篇交叉熵的文章:华为面试官:“交叉熵 (cross entropy) ,KL 散度的值,到底有什么含义?”, 里面有提到通信的问题。
如何把语料用最少的 bit 位传输给模型,其实也是个通信的问题。只不过现在模型参数的通信远高于数据的通信,所以数据 与 GPU 的通信目前还不需要优化。
如果哪一天模型需要大量的输入的时候,tokenizer 的编码效率可能还会被研究。
当前的 tokenization 是否是最优编码?目前只能说有最优编码的影子,但是还不完全是。
比如 BPE 的算法其实就是在构建 Huffman 树,但是构建了之后仍然采用了相同比特位数来编码。这么做的好处省去了解码的过程,直接查表就获取到了 Embedding,但是其实引入解码这点计算量也算不了啥。坏处就是通信上其实还有优化的空间。
还有一点就是中文的编码效率其实理论上还可以更高,因为目前所有的处理流程都是按照英文的流程来的。
比如 subword,对中文就完全没生效啊。之前也举过一个例子,oarfish 我虽然不知道是啥,但是猜测是条鱼。对于中文来说,“鲥”这个字我可能也不认识,但是我也猜测这是条鱼,但是这个字在中文肯定被表示成 bytes 了,就没啥意义了。
所以中文如何高效的编码,也应该是一个研究课题,我甚至感觉中文这种二维的文字,应该和图像的 tokenizer 有某种联系,比如在训练的时候,除了 id embedding,还有这个字对应的图片信息的 embedding。
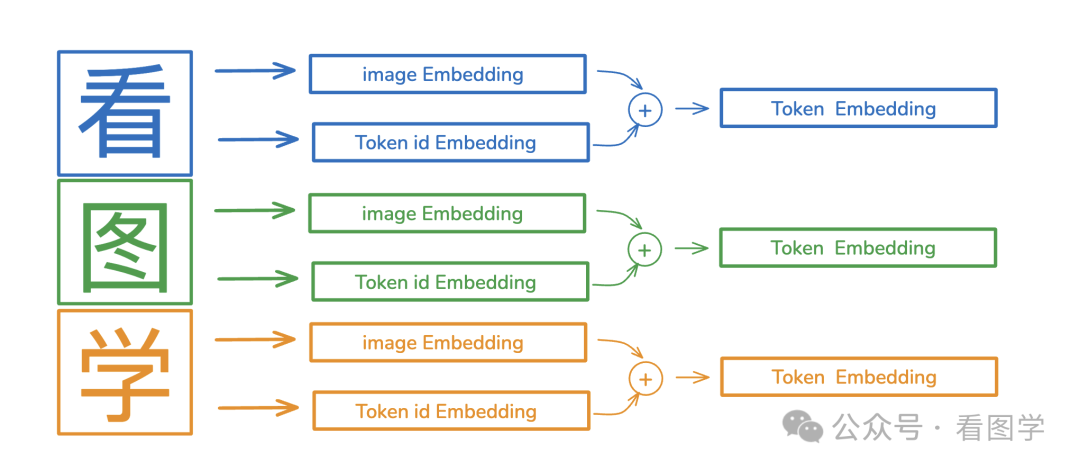
我也不知道这个想法之前有没有人提过,要是没有的话,后续有人研究 id embedding + token image embedding 的话,可以引用一下这篇
4. 交叉熵 (cross entropy) ,KL 散度的值,到底有什么含义?
华为面试官:“交叉熵 (cross entropy) ,KL 散度的值,到底有什么含义?”
5. 说一下 DPO 的原理。
简易版答案
- RLHF 的目的是求一个最优的policy,但是因为 RLHF 的整体上的流程不可微,虽然可以用 TRPO/PPO 等策略梯度算法来优化,但是很耗资源。
- DPO 重新定义了问题,将求解最优的 policy 变成了求解 reward model。
- 在求解 reward model 的过程中,又很巧妙的去掉了无法计算的部分,整个求解过程也是可微的。
- DPO 理论上非常漂亮,实际使用中也能用少量资源达到不错的效果,但是也有很多值得注意的地方。
6. RLHF 为什么不直接对 loss 进行梯度下降来求解?
从强化学习说起
这里先简单讲述一下强化学习和 RLHF,来了解一下 RLHF 的 loss 是怎么来的。
强化学习的目标:假设我们有探索一个未知环境(environment)的执行代理(agent),这个代理可以通过与环境互动来获取一定奖励。代理应当对所执行的动作(action)有所偏好,以最大化累计收益。
举个一般的例子**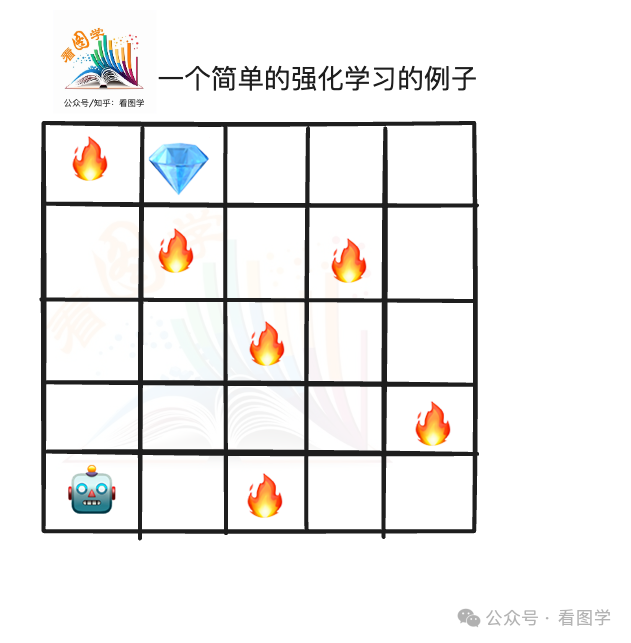 **
**
利用上面的例子来说明一些强化学习的基本概念。
Agent: Robot
State:position (x, y)
Action: 移动到下一个格子
Reward model:
- 移动到空白格子:0分
- 移动到火上:-10分
- 移动到钻石:+100分
Policy:
- 假设action只由状态决定$\pi(a|s)$
语言模型的例子
在语言模型中,对应的强化学习的概念如下:
- Agent: 语言模型
- State:the prompt (input tokens)
- Action: 下一个 token 是什么
- Reward model:
- 人类给生成的结果打分,来确定好坏
- Policy:
- 语言模型本身,因为语言模型的建模就是跟进前面的token去预测下一个。
RLHF
RLHF 是利用人类的反馈训练了一个reward model,其流程如下:
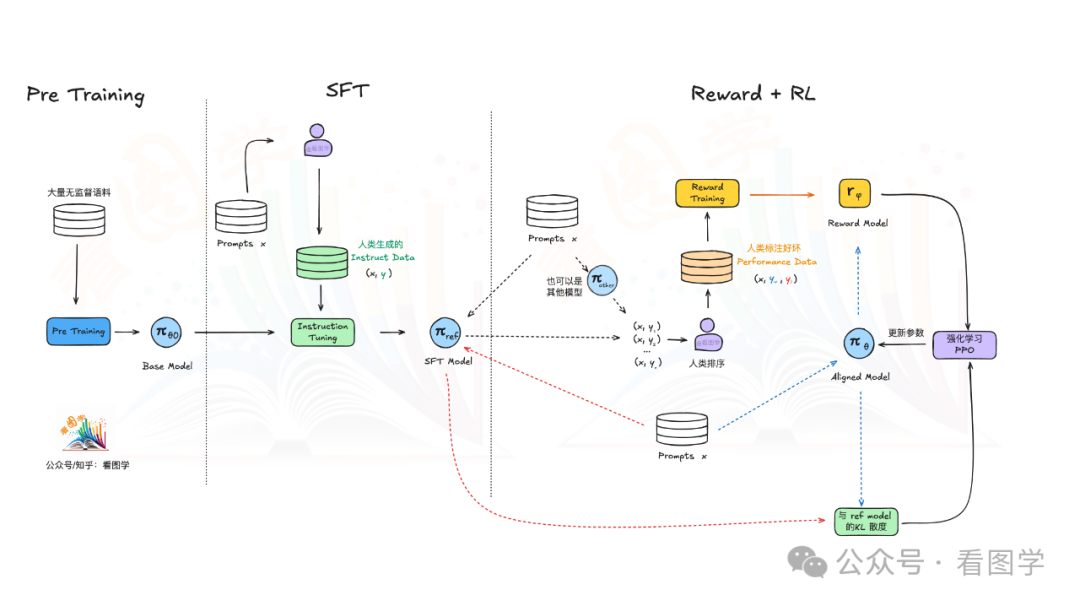
RLHF 也是强化学习,所以最终要求一个最优的 Policy,其优化目标如下:
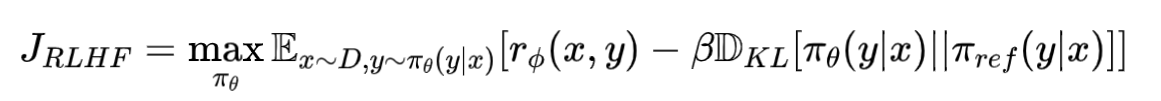
公式的第一部分是强化学习的目标,那就是最大化奖励。
公式的第二部分是一个 KL 散度,用来约束模型要尽可能和优化前的模型接近。
KL 散度用来刻画两个分布的距离,KL 散度越大代表两个分布越不一样。之所以要加上 KL 散度的约束,是因为模型的优化都是贪婪的,如果没有 KL 散度的约束,那训练会一直往 reward model 定义的方向去优化,最后就只会输出reward 分数最高的那一部分结果。那最后模型就只会输出“好好好”,“很赞”这一类无意义的话,通过大量数据训练,花了那么多钱训练出来的base model 的能力都会丢失,变成了电子垃圾。
为什么不直接对 loss 求梯度
核心原因就是因为 loss 或者优化目标不可微,看一下优化目标的红色框部分:
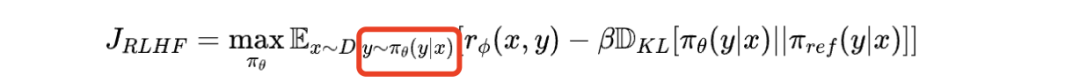
这里的 y 是采样出来的,可能是 greedy,beam search 等,这个操作在词汇表上进行采样或选择,而不是产生一个连续的、可微分的输出。所以也就没法直接使用梯度下降,而是用 PPO等策略梯度来求解。
头条大模型面试:“RLHF 为什么不直接对 loss 进行梯度下降来求解?”
7. 为什么现在深度学习都用 ResNet?
8. KV Cache 原理是什么?
9. 共享权重如何求梯度?
之前的文章:阿里面试官:“Transformers 中的 Weight Tying 是什么?”中有提到过 Weight Tying 技术。把 Embedding 层和最后的 LM Head 层进行了共享,假设共享的矩阵为 W。
我们知道反向传播是一层一层从后往前计算的,但是权重 W 最开始就要计算梯度,然后传播到最后还要计算梯度。
W 的梯度,到底是计算了一次还是计算了两次?
如果是计算了2次,那两次权重是怎么更新的呢?
其实,可以先考虑一个简单一点的例子,就知道答案。
假设
$$
f(x)=xy
$$
$$
g(x)=xf(x)
$$
求 g(x) 对于 x 的导数。这个例子我们一种做法是把式子展开
$$
g(x)=x\times x\times y=x^2y
$$
很容易知道
$$
g^{\prime}(x)=2xy
$$
但是实际神经网络反向传播的计算中,并不是全展开了才进行计算,而是迭代的计算。我们换一种思路来求解:
$$
\begin{aligned}g^{\prime}(x)&=x^{\prime}f(x)+xf^{\prime}(x)\&=f(x)+x\times y\&=xy+xy=2xy\end{aligned}
$$
所以我们就大概猜到,共享权重执行了2次计算,然后结果相加。下面举个具体的例子来说明:
我们假设有一个三层的神经网络,第一层的权重和第三层的权重是共享的,来模拟 Weight Tying 的情况。
$$
\begin{aligned}h_1&=\mathrm{ReLU}(W_1x+b_1)\h_2&=\mathrm{ReLU}(W_2h_1+b_2)\y&=W_1^Th_2+b_3\end{aligned}
$$
假设损失函数为
$$
L=\frac1{NM}\sum_{i=1}^N\sum_{j=1}^M(y_{ij}-y_{true,ij})^2
$$
其反向传播的公式为:
$$
\begin{aligned}&\frac{\partial L}{\partial y}=\frac{2(y-y_{true})}{NM}\&\frac{\partial L}{\partial h_2}=W_1\frac{\partial L}{\partial y}\odot I(h_2>0)\&\frac{\partial L}{\partial W_2}=\frac{\partial L}{\partial h_2}h_1^T\&\frac{\partial L}{\partial h_1}=W_2^T\frac{\partial L}{\partial h_2}\odot I(h_1>0)\&\frac{\partial L}{\partial W_1}=\frac{\partial L}{\partial h_1}x^T+\left(\frac{\partial L}{\partial y}h_2^T\right)^T\end{aligned}
$$
Pytorch 等框架怎么计算?
上面只是从原理上进行演示,但是 pytorch,tensorflow 等工具并不是像上面那样一步一步通过公式推导来进行计算的。而是通过 autograd 的技术来进行。
autograd 细节很多,但是大体上可以理解为整个神经网络都抽象成一个计算图,然后每个节点都有对应的前向传播的计算逻辑,还有对应的反向传播的计算逻辑。整个计算都是在计算图上流动。
对于上面的小例子,对应的反向传播的计算图如下:
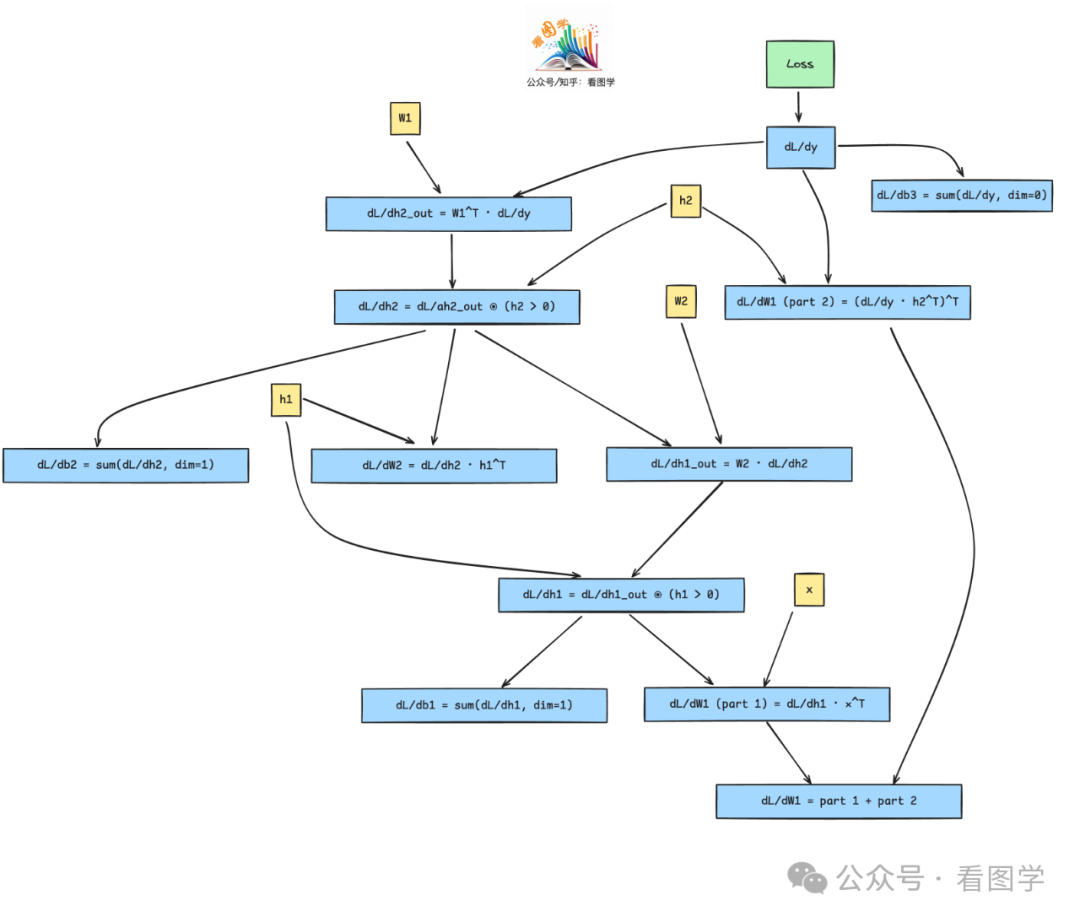
从这里,可以更清楚的看到,共享权重的梯度,在最后是有合并操作的。
代码演示
我们和 pytorch 内部的反向传播进行比较,可以看到,与pytorch 的结果一样。
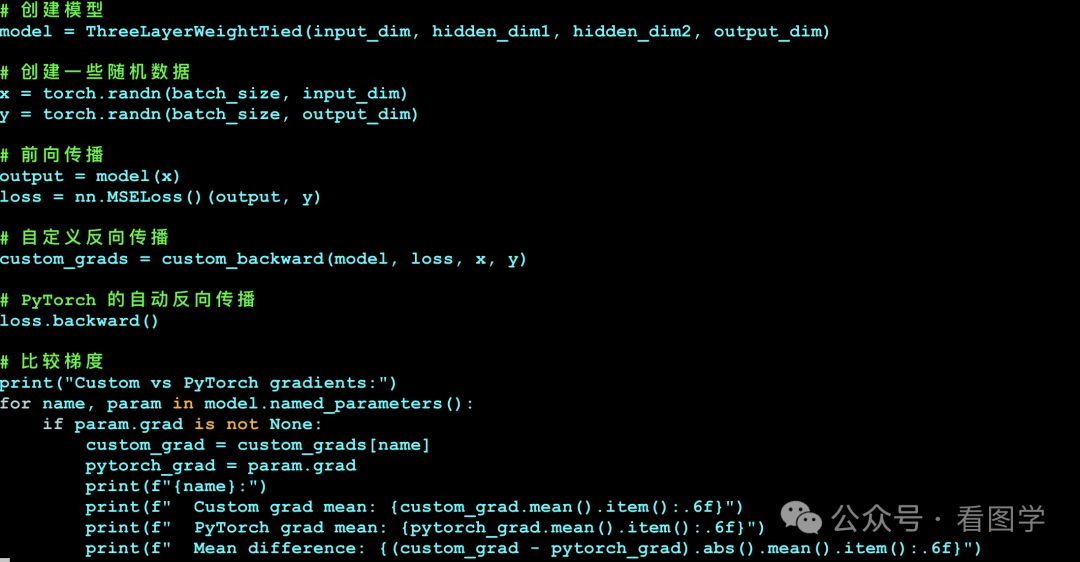
1 | |
10. BF16 和 FP16 的区别?
浮点数如何表示
计算机是二进制的世界,所以浮点数也是用二进制来表示的,与整型不同的是,浮点数通过3个区间来表示。
这三个区间分别是 sign,exponent,fraction.
浮点数的计算逻辑如下,以 BF16 举例(图中的数字是BF16中最接近π的)
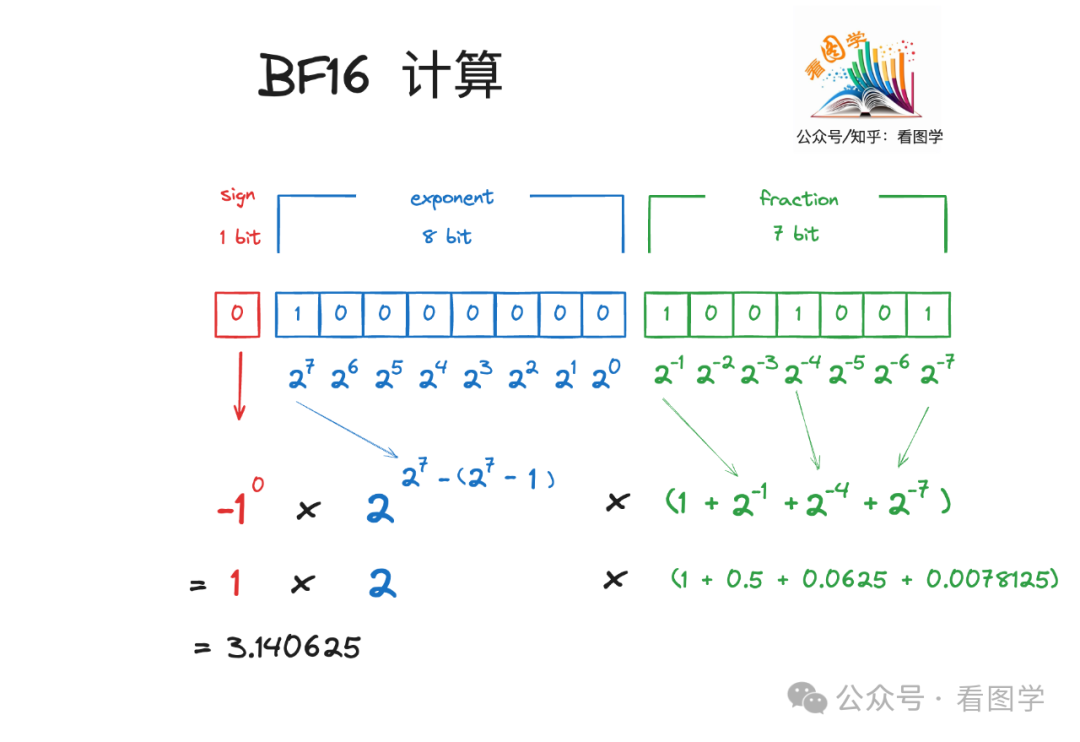
sign 表示正负,和整型一样。
1表示正数,0表示负数。
exponent 用来确定数字的范围
如果这一部分有 k 个bit,这 k 个 bit 的二进制表示的数字为 x,那么这一部分表示的值为$2^{x-(2^{k-1}-1)}$。所以 k 越大,浮点数能表示的范围就越大。
fraction 部分用来确定精度
浮点数的表示,会有一个规范化的动作,那就是所有的数字都会先规范化为 $1.abc\times2^z$这种表示。
比如数字 10.0, 表示成二进制是 B1010.0,要变成 B1010.0 = B1.010 * 23。前面的 B 代表的是二进制的表示。所以实际上 10.0 在二进制里是
$$
2^3\times(1\times2^0+0\times2^{-1}+1\times2^{-2}+02^{-3})=81.25=10.0
$$
而后面这个 1.abc 就是fraction。假设 faction 有 n 个bit,这些 bit 表示的数字为 y,则 fraction 部分代表的数字为$1+\frac y{2^n}$
fraction 的位数越多,就代表有更小的$2^{-i}$ 参加运算,就可以切割的越细,能表示的精度就越高。
最终结果
浮点数的最终结果由上面3部分组合而成, 假设 exponent 有 k 个 bit,bit 的表示的数为 x;faction 有 n 个bit,这些 bit 表示的数字为 y,则表示的浮点数为
$$
\mathrm{sign}\times2^{x-(2^{k-1}-1)}\times(1+\frac y{2^n})
$$
BF16 vs FP16
有了上面的基础知识,就很容易知道 BF16 和 FP16 的区别了。
BF16 一共 16 bit,sign 占 1 bit,exponent 占 8 bit, fraction 占 7 bit。
FP16 一共 16 bit,sign 占 1 bit,exponent 占 5 bit, fraction 占 10 bit。
如下图:

对比 FP16,可以认为 BF16 从 fraction 挪了 3 位给了 exponent。为什么 exponent 选择 8 bit 呢?因为 FP32 的 exponent 是 8 bit。
所以 BF16 能表示的数字范围更大,但是表示的精度更低。FP16 表示的数字范围更小,但是表示的精度更高。
具体差多少呢?可以看下表:

这个表能直观的看到表示范围的差异,BF16 最大可以表示 3.39e+38, 但是 FP16 最大只能表示65504.0
但是精度感觉不太出来,好像 roundoff 也差别没那么大。
但是当数字很大后,所表示的数字就会出现很大的间隔。
以数字 19968.0 举例
- BF16 可以表示这个数字,但是 BF16 可表示的下一个数字是 20096.0, (19958, 20096) 这里面的数字 在 FB16 的世界中是不存在的。
- FP16 可表示的下一个数字是 19984.0,这个要比 BF16 要好一些了,但是仍然有不小的间隔。
- FP32 可以表示的下一个数字是 19968.001953125,FP32 的表示则要好很多,最起码能表示到小数点后3位左右。
神经网络的训练过程中,训练的稳定性很重要,如果用 FP16,则会经常溢出,所以采用 BF16 是个不错的选择,但是精度会损失很多,影响收敛速度。很多数值敏感的运算最好还是采用 FP32,可以采用混合精度训练。还有个问题就是 BF16 目前并不是所有的硬件都支持,但是目前越来越多的硬件都开始支持了。
FP16 则很适合推理,算的快,精度也不错,通信也少。
当然有钱有资源还是用 FP32,上面都是想省钱的产物,各有优缺点。
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
