公众号“看图学”试题合集(4)
Last updated on February 13, 2025 pm
1. 为什么 output token 的价格比 input token 更贵?
翻一翻各大厂家的 API 定价,会发现基本上 输出 token 的价格是输入 token 价格的好几倍。
首先从计算量的角度来看,对于输入的 D 个 token,和输出 D 个token来说,FLOPs 都大约是 2ND,其中 N 为参数量。至于为什么 FLOPs 为什么是 2ND, 可以看这篇:学妹问:“反向传播的计算量是前向传播计算量的几倍?”。
从内存角度来看,输入 token 和 QKV 等矩阵大小和 输出 token 的也差不太多,只不过输出 token 采用 KV Cache 的形式。
既然计算量和内存占用都差不多,从资源的角度来讲,成本是差不多的。那最终成本究竟差在哪里呢?
其实是差在资源的利用率上。
要知道 GPU 在运算的时候,既有计算,又有数据通信。这就存在一个最佳的 ops:bytes ratio。
通俗点来讲,就是每读取一份数据 (比如一个 FP16/BF16), 应该执行多少 FLOPs。
如果算的比读的快,那通信就是瓶颈,因为这个时候 GPU 的 SM 在等待。
如果算的比读的慢,那计算就是瓶颈,这个时候通信需要等待。
大模型训练,大多数情况下,通信是瓶颈,所以都是算的快,读的慢。这样计算下来,整体的 MFU (Model FLOPs utilization) 很难打满。
经过这么长时间的优化,目前大模型的训练 MFU 在50-60% 就已经很厉害了。
回到题目,对于 D 个输入 token 来说,模型只需要执行一个 forward 计算,可以充分的并行,整个计算过程的利用率能接近训练的最高水平。
然而对于 输出 token 来说,必须是一个 token 一个 token 的生成,对于 D 个输出 token 来说,需要执行 D 次 forward 操作。本来通信就是瓶颈,现在 D 次 forward 的额外通信更是雪上加霜。虽然现在也有batch 上,还有动态填充等优化,但是 GPU 利用率上来说,输出是远低于输入的。
假如你是老板,招聘了两个员工,他们干的活是一样多的,消耗资源成本也都一样。一个完成一件事情需要1个小时,一个完成一件事情需要1天,你该怎么发工资呢?
阿里大模型面试原题:为什么 output token 的价格比 input token 更贵?
2. Flash Attention 的数学原理
字节Transformers二面原题:Flash Attention 的数学原理
3. Softmax 如何并行?
Softmax 计算公式

安全的 Softmax 运算
softmax 有个问题,那就是很容易溢出。比如采用半精度,由于float16的最大值为65504,所以只要 $x\geq11$ 那么softmax就溢出了。即使是float32,x也不能超过88。
好在 exp 有这么一个性质,那就是 $e^{x-y}=\frac{e^x}{e^y}.$
根据这个性质,可以在分子分母上同时除以一个数,这样可以将 x 的范围都挪到非正实数域。
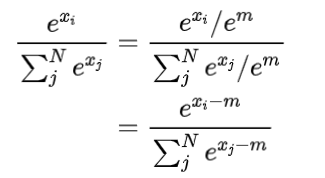
其中$m=max({x_1,x_2,\ldots,x_N})$
这样,就可以保证计算 softmax 时的数值稳定性。
这个算法可以分成三次迭代来执行。

分析上面的步骤,可以发现,如果是不做任何优化的话,至少要进行和 GPU 进行6次通信(3次写入,3次写出)。
如果对每一步的for 循环进行一些并行切分的的话,还要加上 reduce_sum 和 reduce_max 之类的通信成本。
是否能将某些操作进行融合,减少通信呢?按照之前 layernorm 并行的经验,我们需要寻找一个 Online Algorithm。
Online Softmax
2018年 Nvidia 提出了《Online normalizer calculation for softmax》
既然是 Online 的算法,我们需要找出递归的表达式。
对于第二步中的 $d_i=d_{i-1}+e^{x_i-m_N}$, 我们期望去掉这个式子对 $m_N$ 的依赖。
设$d_i^{\prime}=\sum_j^ie^{x_j-m_i}$ ,注意,这里减去的全局最大值变成了当前最大值。这个式子有如下的性质
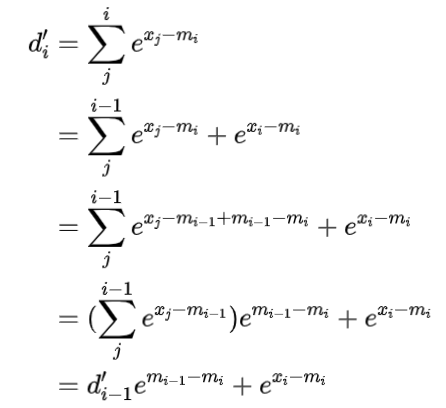
这里可以发现,$d_{i}^{\prime}$ 的计算,依赖于 $d_{i-1’}^{\prime}m_{i,}m_{i-1’}$这样,就可以将前两步合并到一起。上面的3步可以变成2步。

还能不能进一步融合算子呢?没办法了,因为第二步的分母依赖于第一步的计算。
但是可以借助 GPU 的 share memory 来存储中间结果,将上面的两步只用一个 kernel 实现,这样就只需要与 global memory 通信两次,一次写入数据,一次读取结果。
总结
整体来说,有两个重要的优化点:
- 将前两步的算子融合,减少 Reduce_max 和 Reduce_sum 之类的通信成本。
- 借助 share memory 存储中间结果,减少与 global memory 的通信成本。
这一篇只是从数学上给出了一些 Softmax 的并行理论基础。具体实现还有很多细节上的优化点,比如:
感兴趣的可以看看 oneflow 的一个 softmax 深度优化:https://www.oneflow.org/a/share/jishuboke/54.html . 源代码在https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/softmax.cuh
还有 Nvidia 自己实现的一个可读性很好的版本:https://github.com/NVIDIA/FasterTransformer/blob/release/v1.0_tag/fastertransformer/cuda/open_attention.cu#L189-L268 但是速度没有 oneflow 的好。
字节 Transformers 面试原题:Softmax 如何并行?
4. 权重共享是怎么回事?
权重共享(****Weight Sharing )就是在模型的不同部分使用相同参数的技术。有时候也叫 Parameter sharing, 或者 Weight Tying。
权重共享其实可以算作是老技术了,我们可能不知不觉的就在使用,比如 CNN 网络和 Transformers 中的 FNN 层。
CNN 中,同一个卷积核的权重在整个图像的不同位置是共享的。而 Transformers 中的 FNN 层也类似,序列的不同位置共享 MLP。
权重共享有好处:
- 可学习的参数变少了,模型更容易训练,收敛更快了。
- 在内存受限、需要通信的推理场景,能够加快推理速度。
- 权重共享有一定的正则化的作用,因为可学习的参数变少了。所以相当于提升了模型的泛化能力。这个理论可以从 Bias Variance Trade-off 的角度来证明,可以看一篇旧文:码农要术:机器学习篇:泛化挑战
权重共享的坏处:
强扭的瓜不一定甜。一些权重可能理论上在完成任务的功能上就是正交的,共享之后可能会有新的问题。但是这些坏处要具体情况具体分析。比如 词向量与 LM Head 的共享可能导致各向异性的问题。
下面列举一下神经网络中常见的一些权重共享。
基于位置的共享
比如 CNN 和 Transformers 中的 FNN 层。这个不再赘述。
嵌入层和输出层权重共享
这个就是常说的 Weight Tying, 将词向量与最后的 lm head 的权重进行共享。具体可以见:阿里面试官:“Transformers 中的 Weight Tying 是什么?”,里面好处坏处,还有一些分析写的比较清楚。
MQA 和 GQA
MQA 就是 Attention 共享同一个 K 和 V。
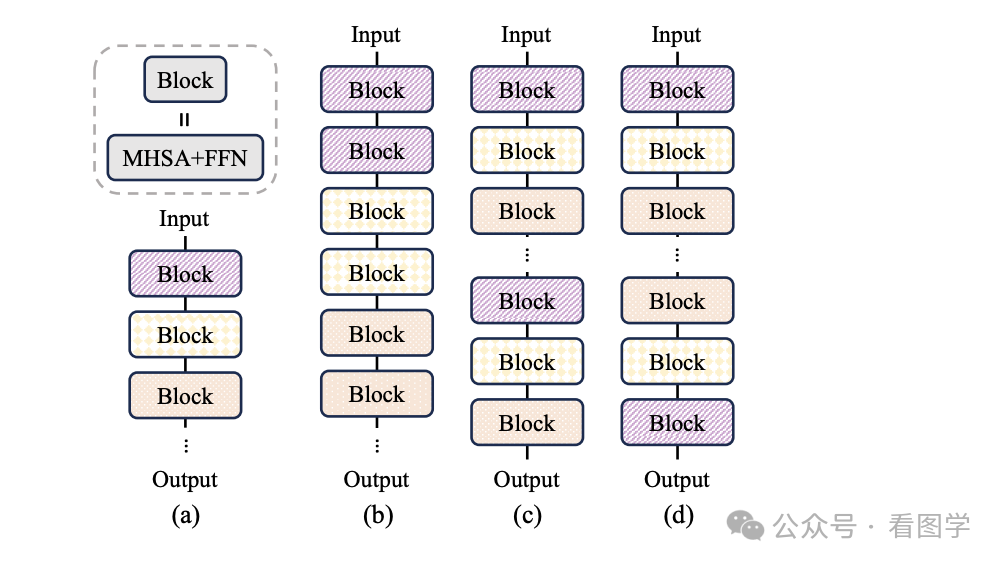
GQA 觉得这样是不是有点太暴力,于是选择了 MQA(共享一个) 和 MHA(完全不共享) 的一个中间形态,按组来共享。如下图所示:
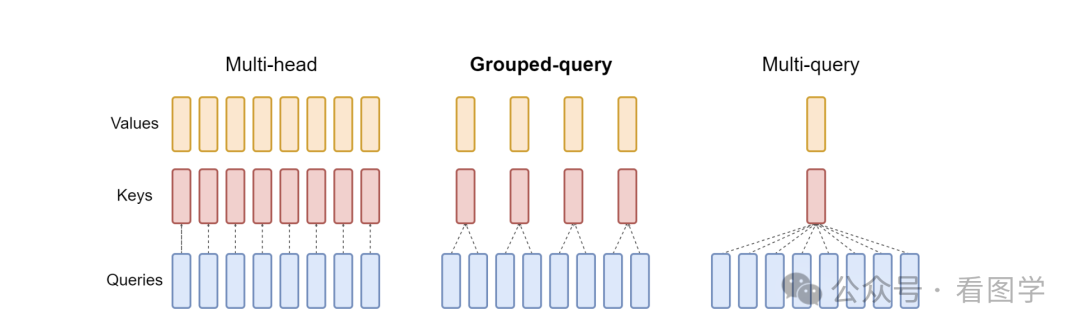
目前使用 GQA 的越来越多了,比如 Llama2,deepseek,yi等。
Layer Sharing (或者 Block Sharing)
将 Transformers 中的 block 进行共享。
早在 BERT 时代,就有人提出了 AlBERT 模型,就是把 Transformers 堆叠的层都用一个来表示。
后来又有 Universal Transformers 和 PonderNet 等模型也做了类似的尝试,但不只是共享那么简单了。
田渊栋团队最新的论文 MobileLLM 中也探讨了 Block 间不同的共享方式。
其他
上面列的都是主流的共享方法。也有很多其他的尝试,但是目前用的不多。
比如 Sharing in branches, Sharing in branches, 还有借助其他方法辅助的。
感兴趣的可以看:
- 《Subformer: Exploring Weight Sharing for Parameter Efficiency in Generative Transformers》
- 《Understanding Parameter Sharing in Transformers》
- 《Pea-KD: Parameter-efficient and accurate Knowledge Distillation on BERT.》
- 《LightFormer: Light-weight Transformer Using SVD-based Weight Transfer and Parameter Sharing. 》
最后,大家可以思考一下,权重共享的模块出现在模型的不同位置时,如何进行梯度的反向传播?
5. Tokenization 是什么
小米面试官:“Tokenization 是什么”。封面看着眼熟
6. 什么是张量并行(Tensor Parallelism) ?
张量并行(Tensor Parallelism) 是一种分布式矩阵算法。
随着模型越来越大,模型内的矩阵也越来越大。一个大矩阵的乘法可以拆分成多个小矩阵的运算,这个些运算就可以充分利用 GPU 的多核还有多 GPU 来进行分布式计算,从而提高运算速度。
Megatron-LM 提出了 1D Tensor Parallelism, 也就是两个矩阵之间的分布式计算方法。后面陆续又有 2D、2.5D、3D Tensor Parallelism。
本文先讲一下 Megatron-LM 的 1D Tensor Parallelism 算法。
1D Tensor Parallelism
其实 1D Tensor Parallelism 的算法完全来源于矩阵运算的性质。如下图所示:

切分方法1
假设两个矩阵相乘,左矩阵按列分割成两个,右矩阵按行分割成2个,那么有如下性质:
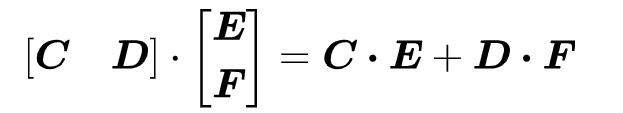
证明如下:

这样的切分方法需要一个 Reduce 操作,因为要把各部分的结果求和得到最终结果。
切分方法2
假设两个矩阵相乘,左矩阵按行分割成两个,右矩阵按列分割成2个,那么有如下性质:
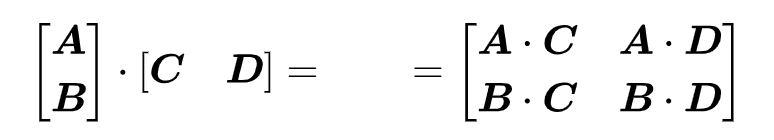
证明如下:

这样的切分方法最终需要把结果 Concat 起来。但是由于每一部分的计算结果都是最终结果的一部分,所以可以不着急 Reduce 结果,可以直接作为下一次并行计算的输入。
两种切分方法组合
假设我们有多个矩阵进行相乘,比如 $\boldsymbol{A}\cdot\boldsymbol{B}\boldsymbol{\cdot}\boldsymbol{C}\boldsymbol{\ldots}\boldsymbol{X}$, 相邻之间的矩阵可以一个横切,一个纵切,然后放到不同的 device 上。从而达到并行计算的目的。

分割成多个也是类似的结论。所以对于矩阵相乘来说,如果有 N 个 GPU,完全可以将参数平分到 N 个GPU上,每个 GPU 只负责计算 $\frac{1}{N}$ 的参数,而不用都塞到一个里面,显存也吃不消。
FFN 的 Tensor Parallelism
来看一个具体的案例。Transformers 的 FFN 层涉及两次矩阵乘法。
$$
\mathrm{FFN}(X)=g(X\cdot W_1)W_2
$$
其中g是激活函数 Gelu。激活函数的非线性导致:
$$
Gelu(X+Y)\neq Gelu(X)+Gelu(Y)
$$
由于有这个激活函数的存在,我们最好按照切分方法2 来进行。因为如果采用第一种,那么需要先进行 Reduce 之后才能执行 Gelu 操作。然后再拆分,再 Reduce。这里有2步 Reduce 操作。
如果采用第二种,则仅需要最后一步进行 Reduce 即可,少了中间的 Reduce 再拆分的工作。如下图所示:
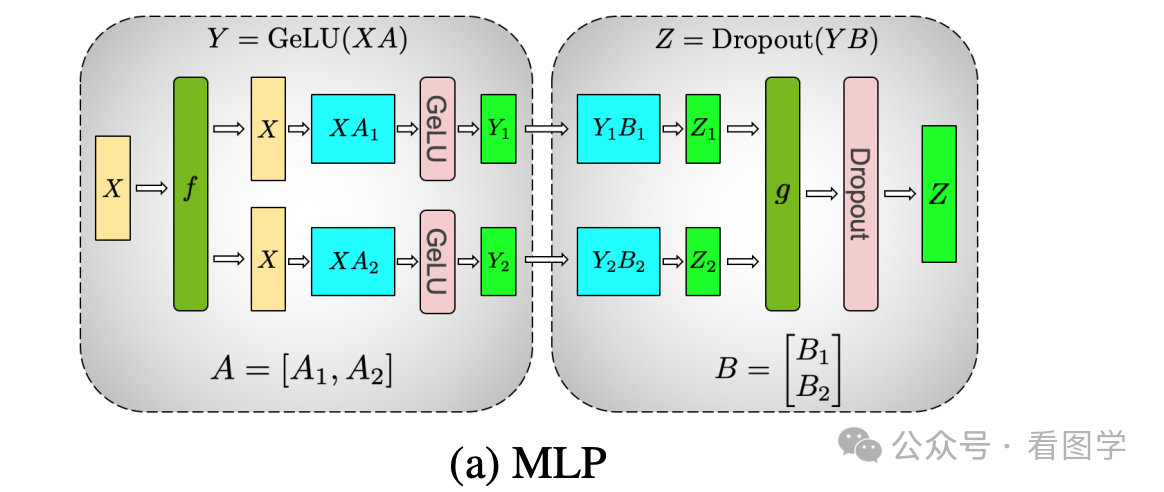
当然这里并没有对 X 进行拆分,仅拆分了$W_1$ 和 $W_2$。要拆分也是可以的。
京东面试官:“ 什么是张量并行(Tensor Parallelism) ?”
7. Transformers 中的 weight tying 是什么?
Transformers 的输入会从一个词向量矩阵中获取对应 token 的词向量,这个词向量矩阵的大小为 (vocab_size, hidden_size)。
在预测一个词的输出概率时,transformer 有个预测头(prediction head), 这个预测头是 Transformers 的最后一层,大小为 (hidden_size, vocab_size),可能还有一个 bias。
如果预测头没有bias的话,这两个矩阵的大小是一样的,如果这两个矩阵使用同一个矩阵,就被称作 weight typing。
这项技术是由两拨人独立提出的,一波人是Ofir Press, Lior Wolf 发表了《Using the Output Embedding to Improve Language Models》,一波是Hakan Inan, Khashayar Khosravi, Richard Socher 提出的《Using the Output Embedding to Improve Language Models》。
这里面比较出名的是 Richard Socher,创办了you.com
下面简单回顾一下这两篇论文关于 Weight Typing 的部分。
Using the Output Embedding to Improve Language Models
这篇文章的出发点是基于词向量和预测头的功能考虑的。作者认为,词向量最终应该满足这样一个条件,那就是相似词的词向量应该也相似(在向量空间中的距离应该更近)。而预测头需要参与 softmax 去预测某一个词,我们期望两个同义词互相交换位置后,得分应该也差不多,这也就要求相似的词在预测头中对应的向量也应该相似才行。
基于这一点的考虑,作者认为词向量和预测头可以共享权重。然后做了一些实验,证明出了结构极其简单的 word2vec,其他的稍微复杂一点的模型,weight tying 之后效果都变好了。
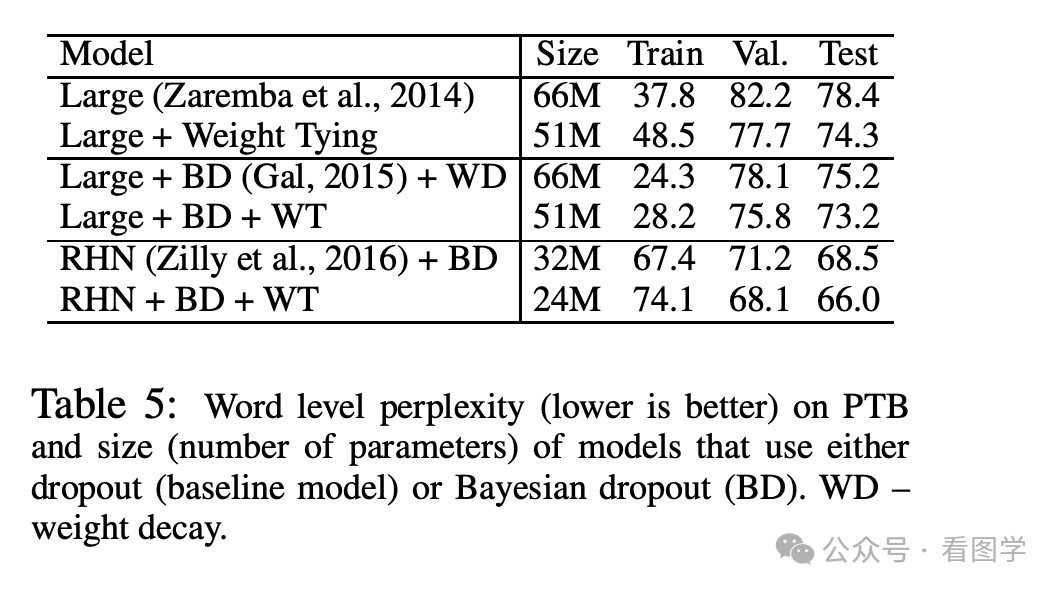
Tying Word Vectors and Word Classifiers: A Loss Framework for Language Modeling
这篇文章提了个新的loss,在这个loss下,从数学上证明了词向量和预测头这两个矩阵的相似性。具体证明有点繁琐,感兴趣的可以看看原文。
Weight Tying 的好处
最明显的好处就是降低了模型参数。
在词表不大的时候并没有什么感觉,但是词表越大,词向量占参数的比例就越大。
比如 llama2 有 32000 个 token ,参数量为 32000 * 4096 = 131072000 个,整体参数量为 6738415616, 占比 1.95%.
llama3 有 151936 个 to,参数量为 151936 * 4096 = 622329856 个,整体参数量为 8030261248, 占比 7.75%.
然而 llama3 并没有使用 Weight Tying, 如果使用的话,参数量会缩减 7.75%,后面会看到,一些词表更大的模型,都用了 Weight Tying。
加速模型收敛
模型参数变小,自然收敛更快。但是从原理上还有另外一层解释。
如果没有 weight tying, 词向量矩阵只会更新自己见过的 token。但是当使用 weight tying 后,所有的 token 的词向量都会更新,即使没见到的 token,模型也会分配合适的概率。
这个问题在 BERT 之类的 Encoder-only 的模型中更为显著,因为每个样本只会预测15%左右的词汇,而不是像 Decoder 那样所有的 token 都会更新。所以 Encoder-only 的模型更喜欢使用 Weight Tying
Weight Tying 的坏处
Weight Tying 也不只是有好处,也有坏处。从根本上说,预测头和词向量所肩负的任务是完全不一样的,强扭的瓜不一定甜。
在论文《Improving Low Compute Language Modeling with In-Domain Embedding Initialisation》 也提到,在一些领域内的低词频的词汇得到充分的训练后,Weight Tying 并没有像 Press & Wolf 那样改善模型的性能。所以更多的语料会削弱 Weight Tying 的效果。
还有在论文《Representation Degeneration Problem in Training Natural Language Generation Models》中提到,使用 weight tying 会导致各向异性问题。关于各向异性可以见 NLP名词解释:各向异性(Anisotropic)
常用模型使用 Weight Tying 的情况
- Gemma: True
- qwen: False
- llama : False
- deepseek:
- yi: False
- glm2/4: false
- glm1: True
- command R: True
- mistral: False
可以看出, Gemma 和 command R 由于词表确实很大(256000 个),使用了 Weight Tying,其他的词表在 100k+ 的搜没有采用 Weight Tying
8. 给一个网络结构,如何计算模型的参数量?
这个题目其实就是问细节,看看对一些网络结构熟不熟悉。
知道了常用的网络结构的计算方法,然后就是加法和乘法了。
一些常见的网络结构列举如下:
Linear
就是个矩阵,有时候会加上个 bias。一个 Linear(in_features=w, out_features=h, bias=True) 的参数量为:w * h + h, 如果 bias = False, 则 为 w * h
Embedding
可以认为是一个没有 bias 的 Linear。
Norm
关于 Norm 的原理和涉及的参数,可以看:NLP面试官:“大模型常用的 Normalization 都有什么?” 算法女生表示易如反掌
- Layer Norm 里面有两个可训练参数, $\gamma$ 和$\beta$ , 假设hidden_size 的大小为 h, hidden_size 的每一维都有两个,所以是 $h\times2$ 个
- RMSNorm 每一维则只有一个可训练参数$\gamma$ , 所以有 h 个
Active 和 Dropout
- 没有可训练参数
举例说明
知道了上面的参数数量,剩下的就是小学数学题了。以 llama3 和 qwen2 来举例:
meta-llama/Meta-Llama-3-8B
可以从论文里查找参数量,但是最方便的还是打印一下模型的结构,代码如下
1 | |
结构如下:

然后挨个计算就可以了:128256 * 4096 + 32 * (4096 * 4096 * 2 + 4096 * 1024 * 2 + 4096 * 14336 * 3 + 2 * 4096) + 4096 + 128256 * 4096 = 8030261248.
所以 llama3 8B 的真实参数量为:8030261248
Qwen 2 7B
如法炮制
1 | |
结构如下:

对比一下可以看出,llama3 和 qwen2 还是有点区别,在 Embedding、Attention 和 FNN 的参数都有所差异。
通过参数,可以看出 llama3 和 qwen2 的词表大小都是64的倍数,具体原因见: NLP 面试八股:“Transformers / LLM 的词表应该选多大?” 学姐这么告诉我答案
通过参数,你能看出 llama3 是 Grouped Query Attention 么?
参数量计算:151936 * 4096 + 32 * (4096 * 2 + 12288 * 4096 + 12288 + 4096 * 4096 + 11008 * 4096 * 3) + 4096 + 4096 * 151936 = 7721324544
所以 qwen 7B 的真实参数量为:7721324544.
我堂堂大学生,不想手动计算
上面是手动计算的方法,利用 pytorch 提供的函数,我们可以很方便的计算出模型的参数量,只需要一行就行,代码如下:
1 | |
9. Pre Norm 和 Post Norm 各自的优缺点?
字节面试官:”Pre Norm 和 Post Norm 各自的优缺点?” 学妹这么回答
10. Transformers / LLM 的词表应该选多大?
答案
先说一下结论:
- 数据量够大的情况下,vocabulary 越大,压缩率越高,模型效果越好。
- 太大的 vocabulary 需要做一些训练和推理的优化,所以要平衡计算和效果。
- 要考虑内存对齐。vocabulary 的大小设置要是 8 的倍数,在 A100 上则是 64 的倍数。(不同的GPU可能不一样)
下面分别说一下这三点.
越大越好
目前已经有很多研究表明,词表越大模型效果会更好。 比如最近刚发的一篇《Large Vocabulary Size Improves Large Language Models》,里面就详细对比了词表大小分别为:5k, 10k, 50k, 100k and 500k 的效果。如下图所示
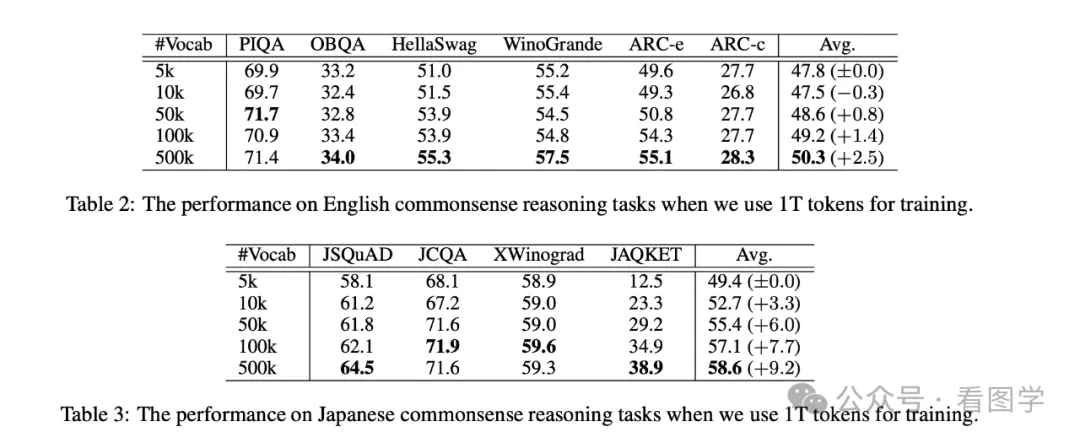
注意这里是完全从头训练的 GPT-3 Large 模型,模型的参数量为 760M。
然后作者还尝试了在 llama 的基础上扩大词表继续训练,扩大了词表后效果依然有提升。如下表所示:

为什么词表变大会更好?个人觉得有如下几个原因:
计算效率的提升
相同的文本,转换为token后越短越好。通常用压缩率来衡量文本转换为token后的压缩比例。
更高的压缩率代表了相同数量的token能够表达更多的信息,相同的信息 token 越短则训练效率更高。
Baichuan 在技术报告里给出的一些模型的压缩率如下
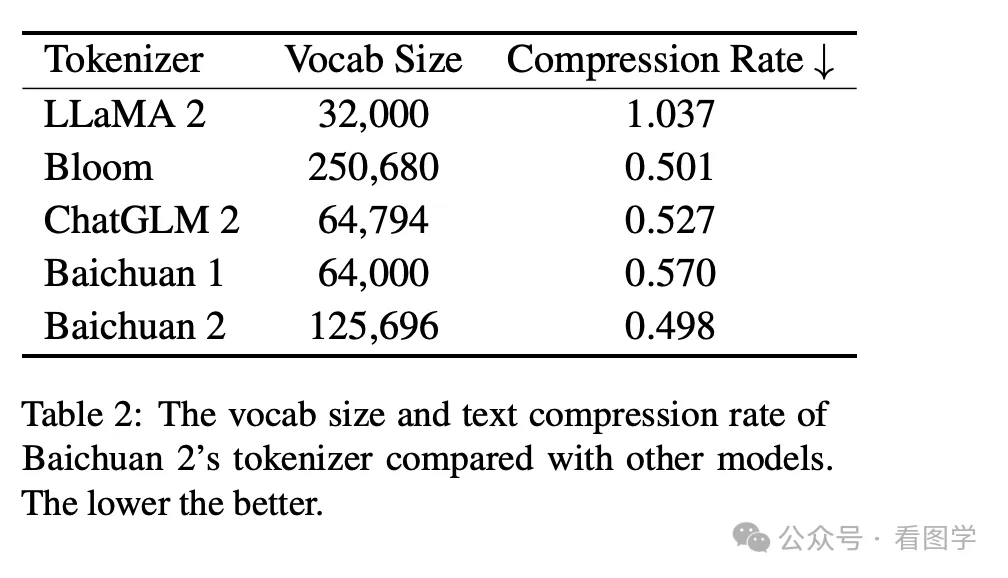 然后千问在技术报告里也提到自家模型的压缩率比其他家更好。
然后千问在技术报告里也提到自家模型的压缩率比其他家更好。
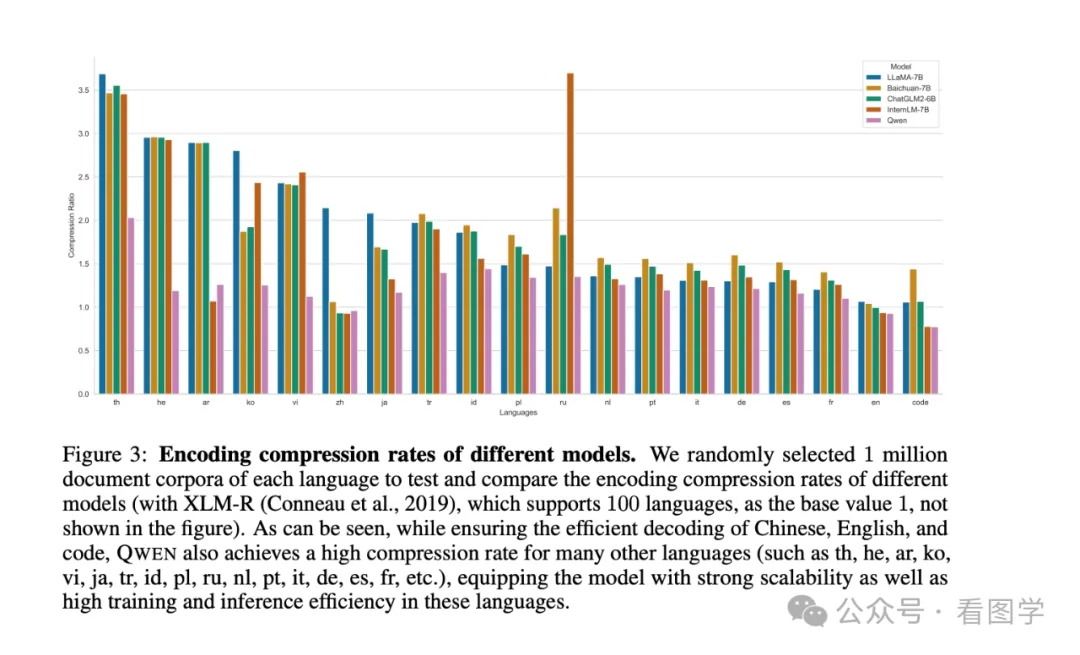
有助于理解文本
更多的词汇能够减少 OOV (Out of Vocabulary)的影响, 训练的信息不会丢失,推理的时候泛化能力也更强。
同时更多的词汇可以减少词汇分解后的歧义,从而更好地理解和生成文本。
更长的上下文
预训练阶段往往都有最大序列长度的限制,压缩率更高代表着能看到更多的上下文,就能 attention 到更多的信息。
还有一些论文比如《Impact of Tokenization on Language Models: An Analysis for Turkish》等也有类似的结论。
计算效率的考虑
虽然 vocabulary 越大越好,但是也不能无限扩大。因为 vocabulary 变大后,Embedding 层变大,最后输出的 Head layer 也会变大。比如 Llama3 将 vocabulary 从 llama2 的 32000 扩展到 128256,参数量就变大了。llama2 还不到7B,但是 Llama3 有 8B了(当然这里面还有其他参数的改动)。
参数更大,更占内存,而且输出的时候 softmax 也更大,计算就更慢。虽然大多数情况下 token 量的减少,整体上是算得更快的。
所以也不能设置得过大,目前业界普遍设置在 10万 到 20万左右。比如 Qwen 的 词表大小为 152064,baichuan2为125696,llama3 为128256,deepseek 为 102400。
多模态的会更大一些。
当然 softmax 过大的问题目前也有解法,可以用 Adaptive softmax,参考论文《Efficient softmax approximation for GPUs》。
内存对齐
之前就有人看到 qwen 的readme 和 训练代码中 vocabulary 的数量不一样, readme 中为 151643,但是实际上代码里写的是 152064。
这就是为了内存对齐。所以很多时候模型上的一些设置其实跟硬件息息相关。
因为最终Embedding 矩阵和输出时候的 Head Layer 最终都会转换成矩阵放到 GPU 的 Tensor Core 中计算。而根据英伟达的开发手册,矩阵运算最好根据 GPU 和计算类型满足如下的条件:
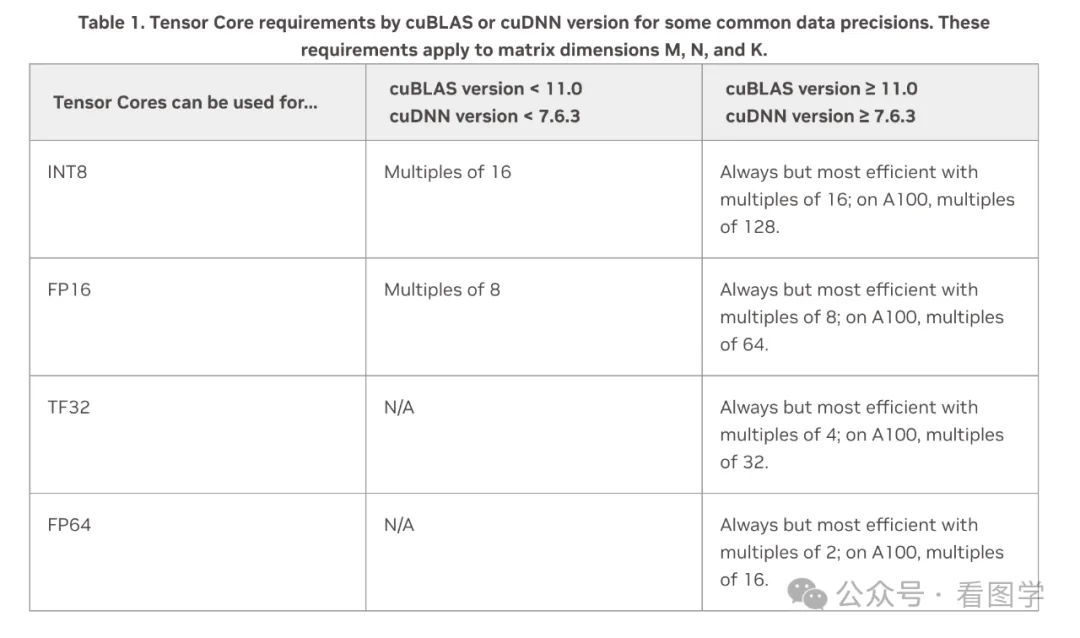
Karpathy 也曾经证实了这一点,他当时写了个 nanoGPT,提升最大的点就是把词表从 50257 改成了 50304,后一个是64的倍数。然后带来了25%的速度上的提升。
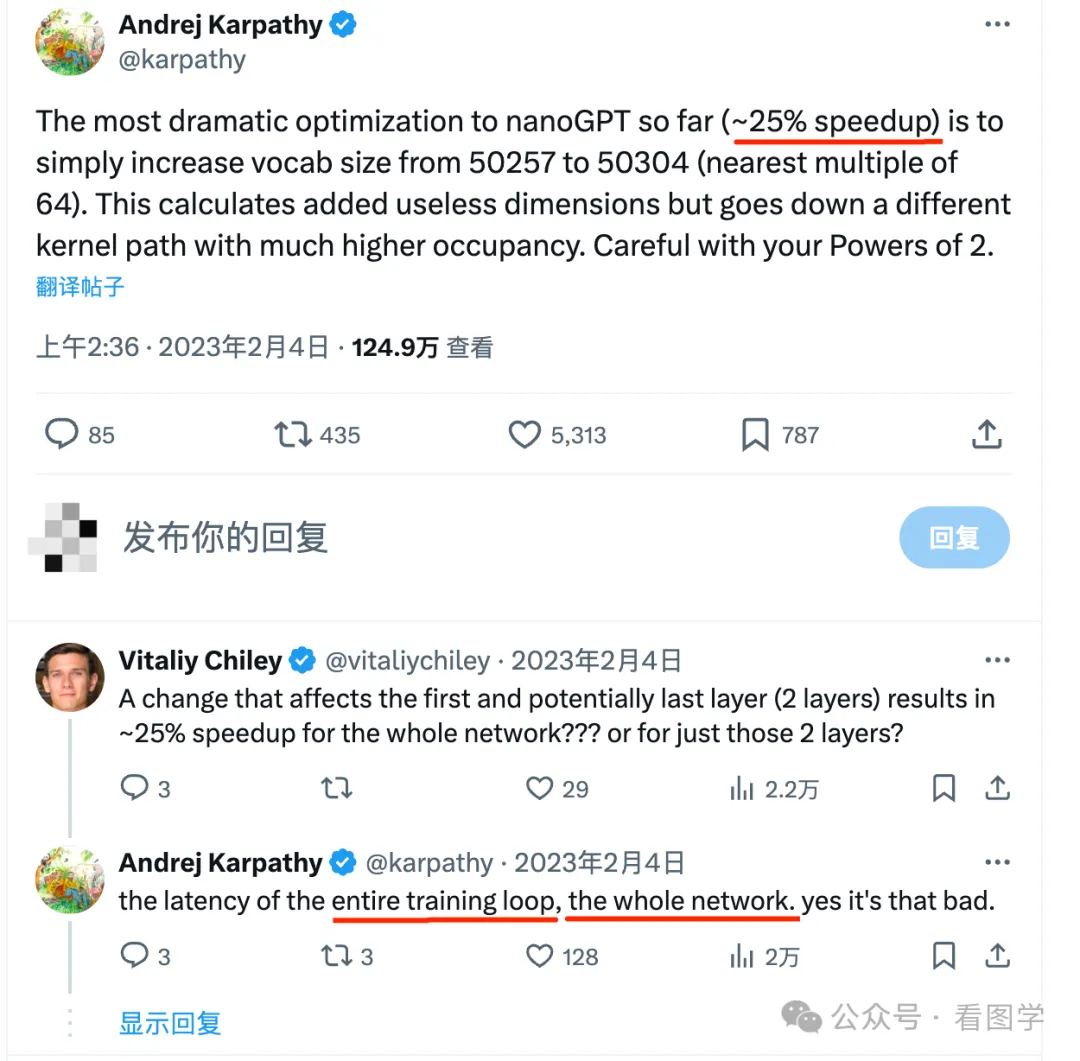
所以目前大多数训练都在 A100 上训练,所以基本上都是64的倍数。如果某个模型的词表不是 64的倍数,那可能不知不觉浪费了很多计算资源。
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
