公众号“看图学”试题合集(5)
Last updated on February 13, 2025 pm
1. RoPE 旋转位置编码
RoPE 旋转位置编码,详细解释(下)NLP 面试的女生彻底说明白了
初中生能看懂的绝对位置编码和旋转位置编码(RoPE),甚至会认表的小学生也行
2. Transformers 中的 Layer Norm 可以并行么?
NLP 面试八股:“Transformers 中的 Layer Norm 可以并行么?” 拿到 offer 的女同学这样回答
3. 大模型常用的 Normalization 都有什么?
- LayerNorm
- RMSNorm
- DeepNorm
- BatchNorm
NLP面试官:“大模型常用的 Normalization 都有什么? ” 算法女生表示易如反掌
4. Transformers 中为什么使用 Layer Norm
为什么使用 Layer Norm
不仅仅是使用 Layer Norm,各种 Normalize 的操作,首先是为了保证训练的稳定性。因为当神经网络很深的时候,反向传播的参数计算往往都是指数级的变化,太大或者太小的数值送入激活函数后就容易造成梯度消失或者梯度爆炸,训练就挂了。
其次是加速模型的收敛。这个也比较容易理解,模型的每一层都在拟合一个数据分布,而如果不进行 normalize,那么每次的输入分布可能随时都在变化,这样学习起来就很困难。在 normalize 之后,绝大部分数值都集中在了一个可接受的范围内,每一层的参数就安心拟合这个分布就好了,这个范围正好又是激活函数的“舒适区”,所以模型收敛速度会更快。
还有一个额外的好处就是让模型的训练不再那么依赖权重的初始化,早期的时候初始化对模型结果的影响还是蛮大的,也是个很火热的研究方向。就包括现在也有很多研究,比如 torch.manual_seed(3407) is all you need
为什么不用 Batch Norm*
其实在 Transformers 论文刚出的那个时间点,就是两种 Normalize 比较流行,早一点提出的是 Batch Norm, 后来是 Layer Norm, 至于再后来的 Instance Norm 和 Group Norm 等都可以认为是这两种基础上的扩展。
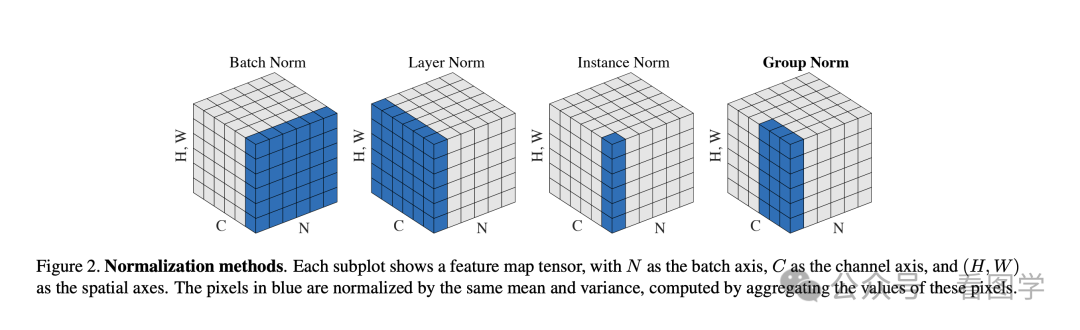
当时 Batch Norm 在 CV 领域比较流行,而 NLP 则使用 Layer Norm 比较多。但也并不是一定要按照任务这么划分。
当时为什么 CV 都使用 Batch Norm 呢?我个人觉得是因为站在 CNN 卷积核的计算方式上看,在 Batch 上进行 Normalize 是比较契合的,因为这样每个卷积核在计算的时候数据的 Normalize 的方式是一样的。
但是 Batch Norm 也有些问题,下面简单说几点:
- Batch 需要大,小的 Batch 训练不稳定。因为 Batch Norm 需要跨样本的 Normalize,所以采样要足够大才能捕捉到样本的分布。
- 加大 Batch 有一些副作用。一个最明显的问题,那就是现在模型越来越大,如果想实现多机多卡的 GPU 并行,那 Batch Norm 需要额外的通信,因为一个 Batch 很可能分布在不同的机器上,而 Normalize 又需要计算整个样本的数据分布才行。现在大概有两种解法,一种是类似 mini batch,放弃跨机器通信;一种是 Pytorch 实现的 SyncBatchNorm,在前面的基础上尽量减少通信的数据。但是不管怎么样,额外的通信开销在模型足够大的时候也是个问题。
- 训练和预测的不一致性。训练的时候有大批的数据可以组成 Batch,但是预测的时候,我如果只想预测一个样本,那 Batch Norm 就废了。所以在预测的时候实际上是采用了训练时候的数据分布来进行 Normalize 的。这样就必须要保证训练和预测的分布必须一致,泛化能力没那么强。
- 并不适合当时的 NLP 主流框架比如 RNN。
- 并不太适合长度不固定的 NLP 序列。因为每个 Batch 最后总有些 pad,这些 pad 会干扰 Batch Norm 的数据分布。如果把 pad 都不参与计算,那就相当于 batch 越来越小,根据第一条也不太好。
关于数据分布还有 Batch 的讨论,可以看下论文 Facebook 的《Rethinking “Batch” in BatchNorm》,其中还提到了 Batch 内的信息泄漏等问题,感兴趣的可以阅读一下原始的论文。
所以说 Layer Norm 改成了按 特征 来 Normalize,可以很好的处理小 Batch 和变长输入的问题,也没有额外的通信,可以说基本解决了上面的问题。
所以后来 Layer Norm 越来越流行, Batch Norm 反而不太用了,尤其是大模型时代一直在追求更高的训练效率, Batch Norm 的额外通信就有些不合时宜了。当然现在大模型也有其他的 Normalize 方法,比如 RMSNorm、DeepNorm 等。
实验论证1:Transformers 使用 Batch Norm 效果并不太好
上面说了一些 Batch Norm 和 Layer Norm 的对比,有人可能会说你这都是理论上的,有证据么?还真有,2020年的一篇论文专门测试了把 Transformers 中的 Layer Norm 变成了 Batch Norm,打了个擂台。论文的名字是《PowerNorm: Rethinking Batch Normalization in Transformers》
这篇论文中,作者发现 Transformers 中的 LayerNorm 换成 Batch Norm 后,在分类和机器翻译的任务上性能下降明显。如下图
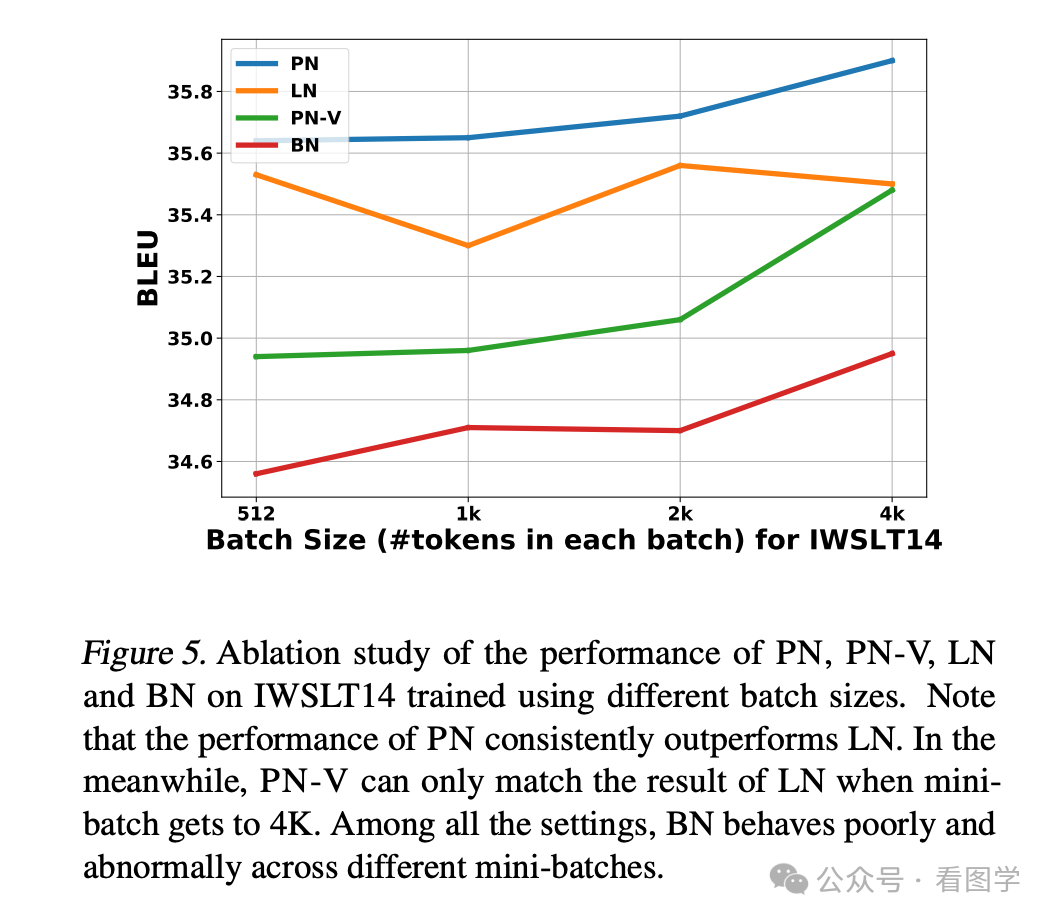
可以看出,Batch Norm 效果并不太好。分析其原因呢,作者指出采用 Batch Norm 的 Transformers, 其 Batch Norm 的均值和方差震荡明显,并不稳定,所以收敛的就很慢。
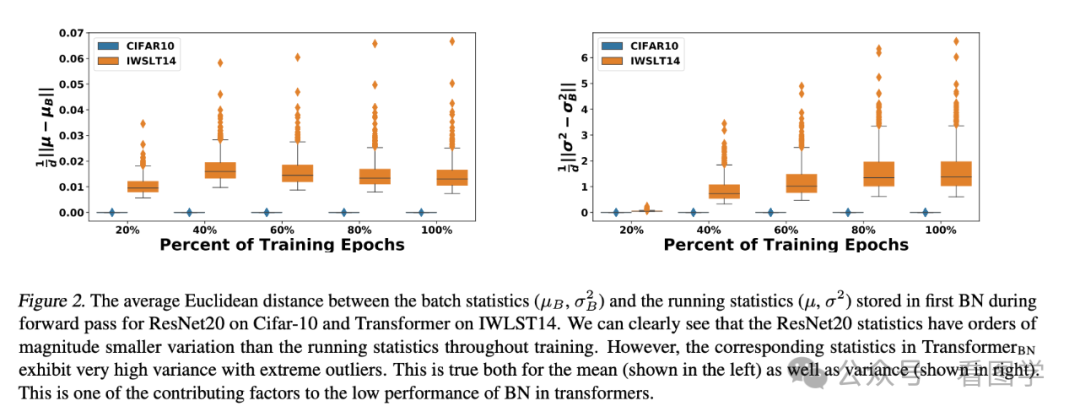

当然作者后来对 BN 进行了改进,提出了 PowerNorm, 感兴趣的可以看看。
实验论证2:Layer Norm 会改善 Transformers 的注意力
来自2023年的论文:《On the Expressivity Role of LayerNorm in Transformers’ Attention》
这篇文章在较小的 Transformers 模型上做了实验,发现 Layer Norm 为 Attention 提供了两个功能
- Projection:会将输入投影到 query 和 key 正交的超平面,这样方便所有的 key 可以同等访问。
- Scaling:每一个 Key 都能被选中,都有机会获得最高分。
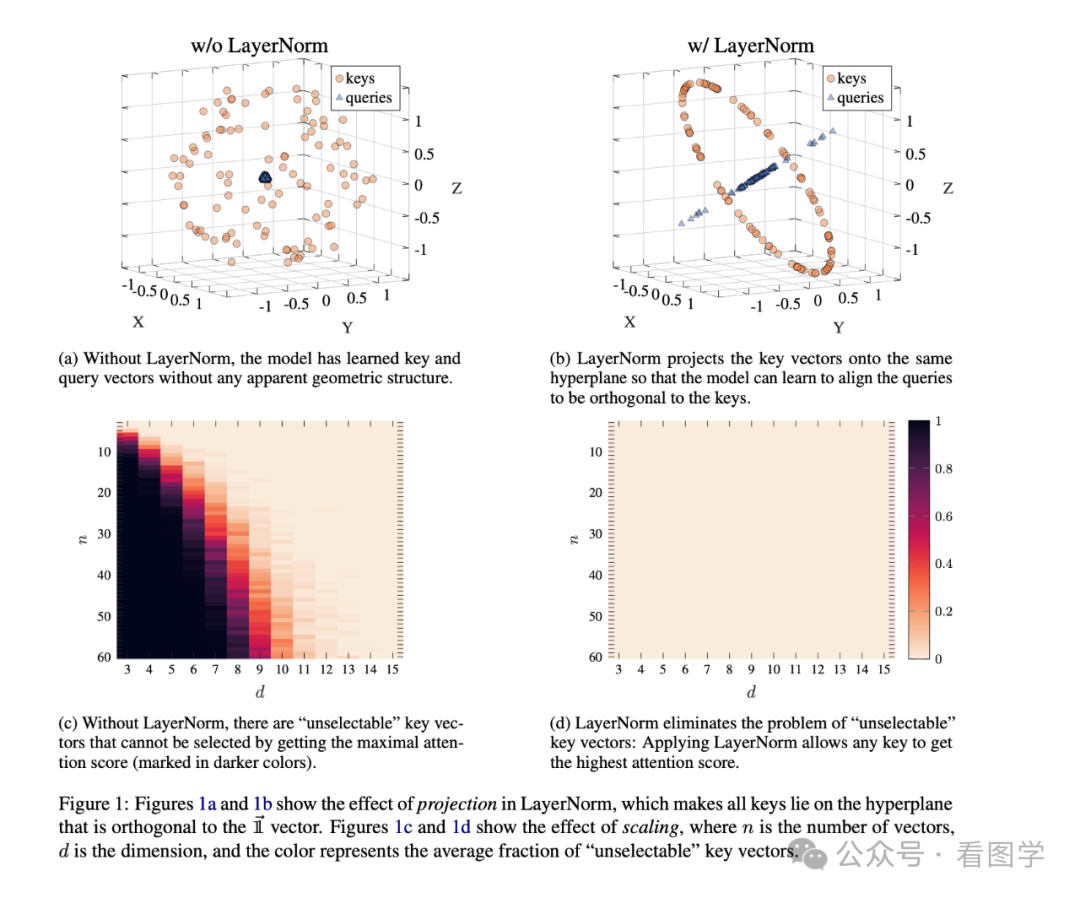
Layer Norm 的存在可以让 Attention 不用自己去学习这两点。但是随着模型规模的增大,这个辅助作用是被削弱的,也就是模型能自己学会这两点。但是仍旧从一个比较有意思的角度阐述了 Layer Norm 的作用。
实验论证3: Layer Norm 在图像中表现怎么样?
2018年,何凯明提出的 《Group Normalization》对 ResNet 中使用不同的 Normalize 方式进行了对比,可以看出 Layer Norm 是不如 Batch Norm 的
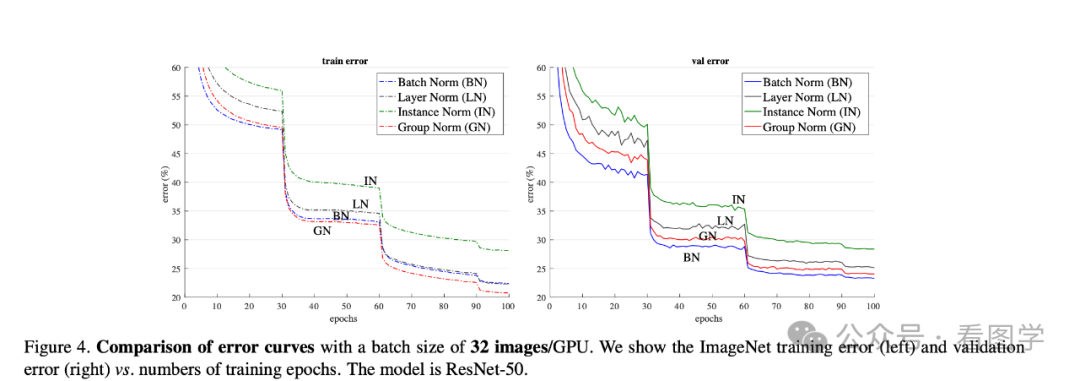
在 Transformers 大火后,CV 领域也开始使用 Transformers,Vit 中使用的就是 Layer Norm.
2022年的一篇文章,也是何凯明之前所在的 FAIR 小组,发表了论文《A ConvNet for the 2020s》,论文里表示,在借鉴了一些 Vision Transformers 的思想对 ConvNet 修改后,使用 LayerNorm 效果比 Batch Norm 还要好一点。
NLP面试官:“Transformers 中为什么使用 Layer Norm ” 算法女生这么回答轻松拿下
5. Transformers 中的 Position Embedding 的作用
NLP面试官:“Transformers 中的 Position Embedding 的作用” 算法女生这么回答就很赞
6. Transformers 中 FFN 的作用
NLP面试官:“Transformers 中 FFN 的作用” 算法女生这么回答下午就想安排入职
7. Attention为什么要除以根号d
NLP面试官:“Attention为什么要除以根号d” 算法女生这么回答当场想发 offer
8. 如何根据模型参数量估计需要的显存?
9. 如何让大模型处理更长的文本?
文章合集:chongzicbo/ReadWriteThink: 博学而笃志,切问而近思 (github.com)
个人博客:程博仕
微信公众号:
